

A Systems Engineering Presentation to the Open Source Architects (OSA) Community
From the theoretical background of how we think about the problem of architecting knowledge to practical examples, Dr. Zargham presents collaborative research and work to the OSA community, offering a systems engineering perspective on how we design, implement, operate, and govern our knowledge infrastructures.
Holding a Ph.D. in electrical and systems engineering from the University of Pennsylvania. Dr. Michael Zargham is the founder and chief engineer at BlockScience and board member and research director at Metagov, a US-based nonprofit focused on digitally mediated self-governance. In addition to lecturing and multiple advisory roles, he is a trustee of a data trust called Superset and an advisory council member at NumFocus, an organization promoting open practices in research, data, and scientific computing.
Watch BlockScience Founder and Chief Engineer Dr. Michael Zargham presenting Architecting Knowledge Organization Infrastrucuture, hosted by OpenTeams.
In open-source software communities, knowledge organization infrastructure (KOI) — centered around platforms like GitHub — facilitates everything from contribution guidelines to project tracking and artifact management. But what happens when communities are not as clearly structured or governed by software-centric tools? In this talk, Dr. Michael Zargham, founder and Chief Engineer at BlockScience, explores KOI through two distinct lenses — a systems engineering firm and a social science research non-profit — and provides insights into designing and implementing KOI within non-software settings. Source: Open Teams
This post shares the presentation video and transcript, with the addition of selected slides and research papers referenced in the presentation. Topics include:
- Systems Engineering Perspective on Architecture
- Institutions, Infrastructures & Feedback Systems
- Four Levels of Abstraction in Architecture
- What is Knowledge Organization Infrastructure?
- Conceptual Architecture for KOI
- What is Knowledge Organization Infrastructure "made of"
- Devil's in the Details: Gathering Requirements
- Examples from Metagov's Knowledge Organization Infrastructure
- KOI Pond & Demo
Architecture: Systems Engineering Perspective

As a systems engineer - rather than a software architect - with experience in designing complex systems such as robots, business decision systems, and systems that encompass human, legal, and operational processes, it is important to emphasize the meaning of "Architecture" from a systems engineering perspective.
An architecture is a specification for the arrangement of parts into a system. The same set of components can form different systems depending on how they are organized, and the organization largely determines the behavious and properties of the system.
In fact, the same components can produce many different behaviors depending on how they're organized relative to each other. And so much of this discussion is focused on using almost out-of-the-box components (wherever possible) and organizing them in new and interesting ways to achieve our goals from a behavioral perspective.
Institutions, Infrastructures & Feedback Systems
Applying Douglas North's canonical definition, an institution is a humanly devised constraint that structures political, economic, and social interaction. In contrast, infrastructure is the basic physical and organizational structure(s) and facilities needed to operate a society or enterprise.
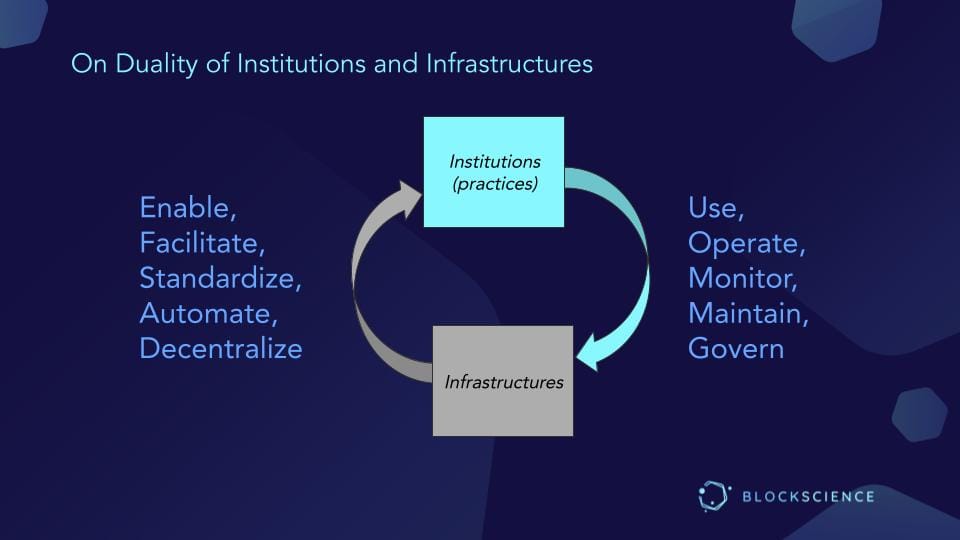
If we consider our own organizations, where we establish practices, human constraints, and activities - and develop infrastructures that enable, facilitate, standardize, automate, and decentralize the various practices - we can see that practices are used for operations, monitoring, maintenance, and governance of the infrastructures. This is especially true when discussing digitally mediated organizations, whose infrastructures are technical.
As a systems engineer, this problem can be approached through a standard engineering validation and verification V, but I've broken it down into something a little more commensurate with a startup or software development mindset where we are thinking about narrative models in terms of storytelling, but also requirements and user stories and theories of change, from which we digest designs and metrics for testing. If you're doing test-driven development, your tests might best represent your intended design, but ultimately, those models have to be compared against human expectations.
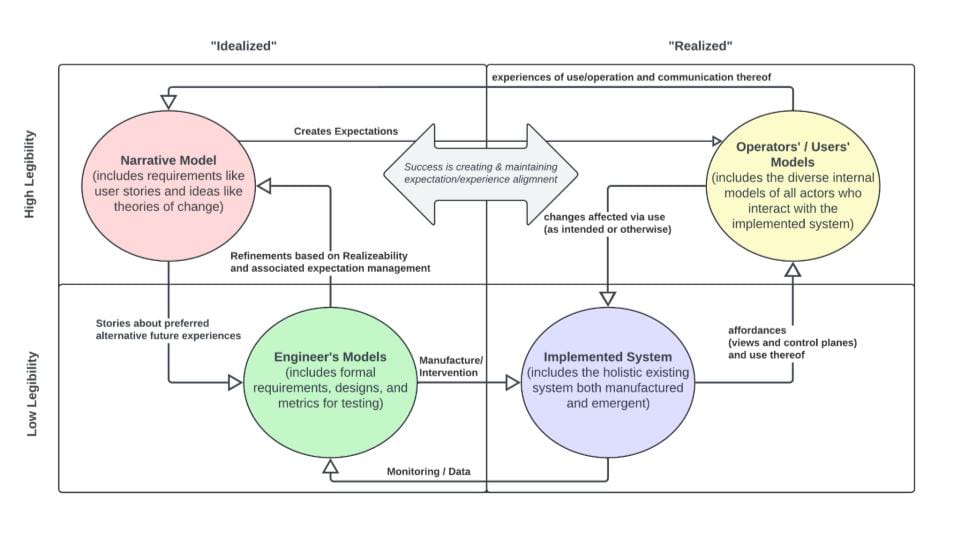
There's always a gap due to the legibility difference between people's stories and formal specifications. However, formal specifications are what we use to implement, and implementations can be verified against those specifications. Implemented systems also have users, operators, and experiences produced by using or operating those systems. Of course, we get validation when we consider whether the system is producing the intended outcomes. When we go back and forth comparing the user's experiences against the narratives and comparing the user's experiences and their commentary about those experiences, we produce new narratives.
Effectively, you end up with a closed-loop system interacting between the technical, potentially very complex systems and the desired experiences and the lived experiences of the users and operators. We view these systems as successful when we can align people's expectations. That doesn't mean that everyone always gets everything they want because the real world is full of trade-offs, but ultimately, setting expectations that can be met and meeting them, and then continuing to maintain that alignment, is tantamount to governance.
Four Levels of Abstraction in Architecture
In systems engineering, we discuss architecture at various levels of abstraction. Jumping between layers often leads to confusion, so we define below the four levels of abstraction from a systems engineering perspective.

Conceptual Architecture: The high-level vision or abstract framework of a system defining the purpose, key objectives, and major components without specifying their implementation details. It focuses on the "what" and "why" of the system.
Functional Architecture: A detailed breakdown of the system's functionality, describing "what" the system must do to meet its objectives. It has the key functions and their interactions but remains independent of specific technologies.
Logical Architecture: A translation of the functional architecture into a structured layout of abstract components, their interactions, and data flows. It specifies the "how" the systems will achieve its functionality but avoids commitment to an implementation.
Physical Architecture: The concrete implementation of the logical architecture, specifying actual hardware, software, and physical components. It defines the "where" and "with what" the system will be built and operated.
Working from conceptual through functional and logical to physical is how we architect particularly complex things, especially when aspects of functional architecture are not implementable; they just exist in the world. This is commonly the case when you are dealing with systems with humans in the loop, for example, when you are concerned with a group of stakeholders who are directly participating, and the system that you are architecting accounts for both their contributions and their expectations and needs.
What is Knowledge Organization Infrastructure?
Knowledge organization infrastructure (KOI) is systems, tools, processes, rules, and governance mechanisms that enable the collection, curation, management, sharing, and utilization of knowledge within a specific context. It encompasses both the technical and social components required to ensure that knowledge is discoverable, accessible, reliable, and actionable to serve its stakeholders' needs.
The key here is that we are not just talking about a particular data commons or pool of data; we are talking about incorporating into a specific operating context for a specific group of people doing a specific thing. This means that they have specific desires, wants, and needs, and they have specific limitations, and resources to spend to maintain and use that pool of knowledge. To this point, I'm going to briefly review some material from a paper called Why Is There Data?
Abstract: In order for data to become truly valuable (and truly useful), that data must first be processed. The question animating this essay is thus a straightforward one: What sort of processing must data undergo, in order to become valuable? While the question may be obvious, its answers are anything but; indeed, reaching them will require us to pose, answer – and then revise our answers to – several other questions that will prove trickier than they first appear: Why is data valuable – what is it for? What is "data"? And what does "working with data" actually involve?
Closed Loop System Model
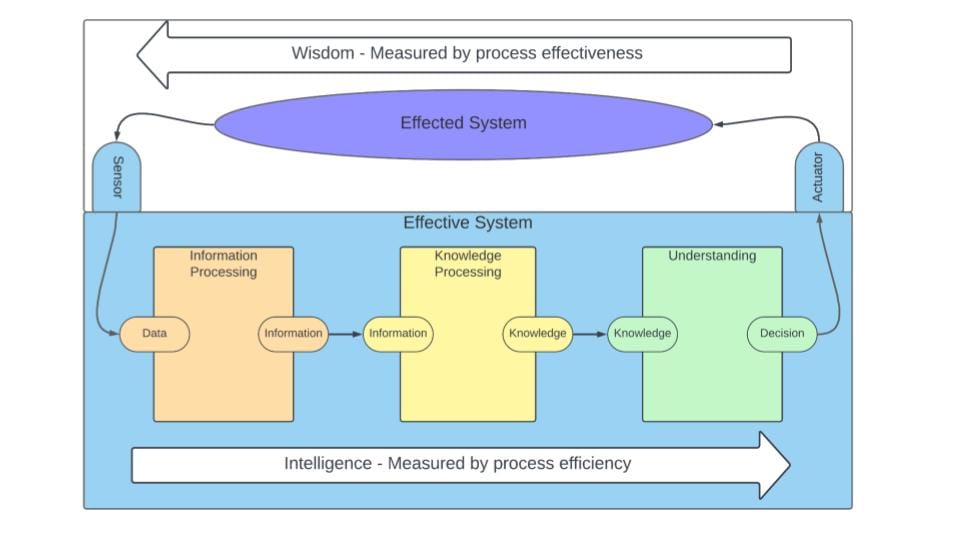
Starting with this closed loop system model, which shows a feedback loop from what you can think of as raw serialized data collected from some location out in the world, whether that is a physical sensor or an online platform, we are suggesting that this is low-level event data of some kind.
This model shows that raw facts undergo information processing first, but where we are focused today is on knowledge processing, understanding how we move from an information-processing way of reasoning onto a knowledge-processing way of reasoning and how that serves understanding. This model depicts that we take knowledge into context and render decisions that affect the world.
The consequences of those effects on the world may give feedback to us through our sensors and our observation, but at the end of the day, this ongoing loop is something that we can think of as effective if we are able to produce the desired or intended effects, as distinct from how efficiently can we process data.
A lot of the time, when we talk about intelligence, especially artificial intelligence, there is a tendency towards focusing on efficiency and scale throughput, but not necessarily as much focus on the quality of outputs and whether they are actually having the intended or the desired effects.
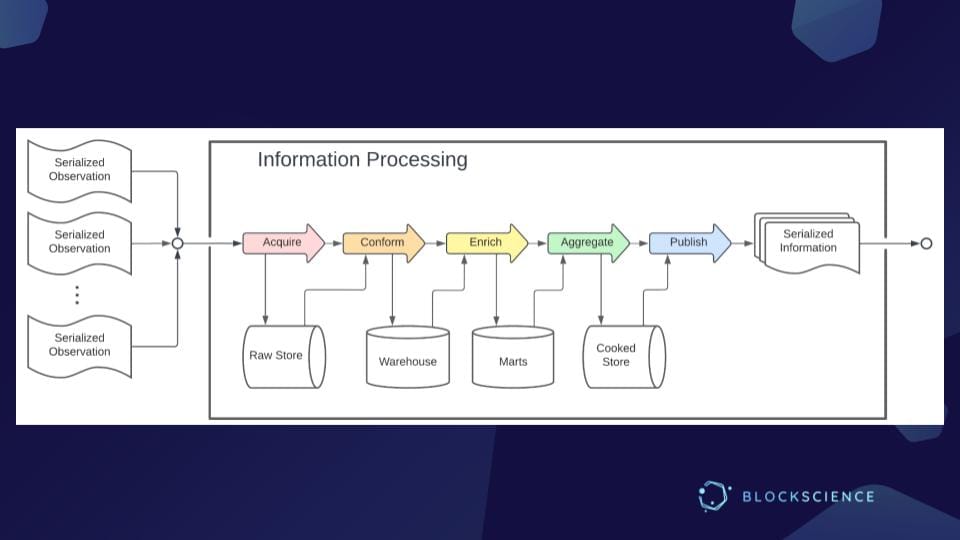
With traditional information processing we acquire data, store and conform it, which means we standardize it to a particular schema.
We can enrich records by joining and connecting fields from other data sources. We can aggregate, group, and compute statistics. Maybe we learned some machine learning models, but at the end of the day, the output is at a higher level. Low-level data without some sort of confirmation enrichment and processing is not super useful for us just yet. So, as those serialized data sets come out, we can think of them as feeding into knowledge processing.
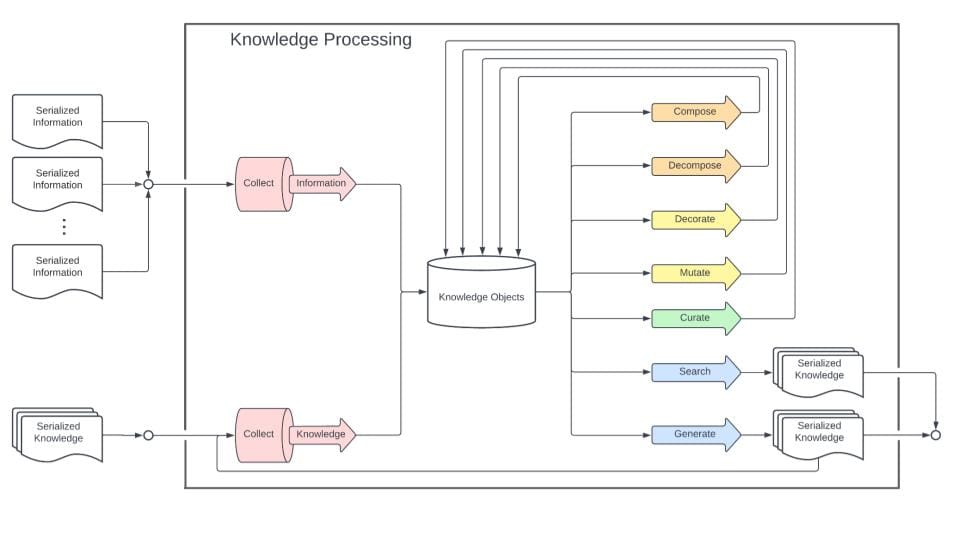
Knowledge processing is fundamentally different from information processing under this model because it's circular.
It is not item potent. It's not something where we would expect the same results. If you apply the same operation to an object, you will get a new object. The kinds of operations that we are interested in are;
- compose, combining things
- decompose, breaking things down
- decorate, adding additional information
- mutate, revising &/or editing
- curate, filtering & new combinations
- search, discovery of existing
- generate, new objects
You can see there is a feedback loop baked in here that the knowledge processing stage is meant to be more circular, yet this is also feeding into a process that we refer to as understanding, which you can think of as a more deliberative process. It still involves knowledge objects - papers, open-source software projects - higher-order objects that are not just the data.
Understanding is about consolidating that information into things that describe what's going on or interpret and render it ready for input to a human sense making process which is the interesting part.
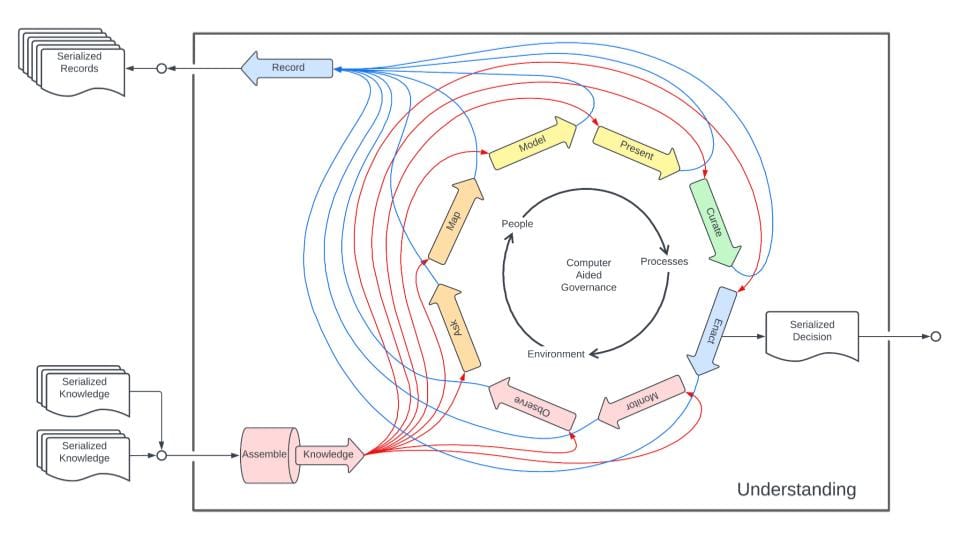
This diagram [above] is a derivative of some early work on a concept called computer-aided governance, where we take principles of data-driven decision-making in business and apply them to participatory governance. Imagine having a data science team or a participatory citizen science team within a community working to make sense of what is going on and helping to make policy, rules, and decisions.
And so, we see knowledge objects as inputs to the understanding process, leading to deliberation and discussion processes that can produce additional knowledge objects.
For example, if you do an analysis or a scenario plan to share with other community members as support for a proposal that you are making, whether or not that proposal gets passed, that analysis or that proposal can effectively be recorded, serialized, and stored as a knowledge object.
Knowledge within the Context of an Open Source Software Project
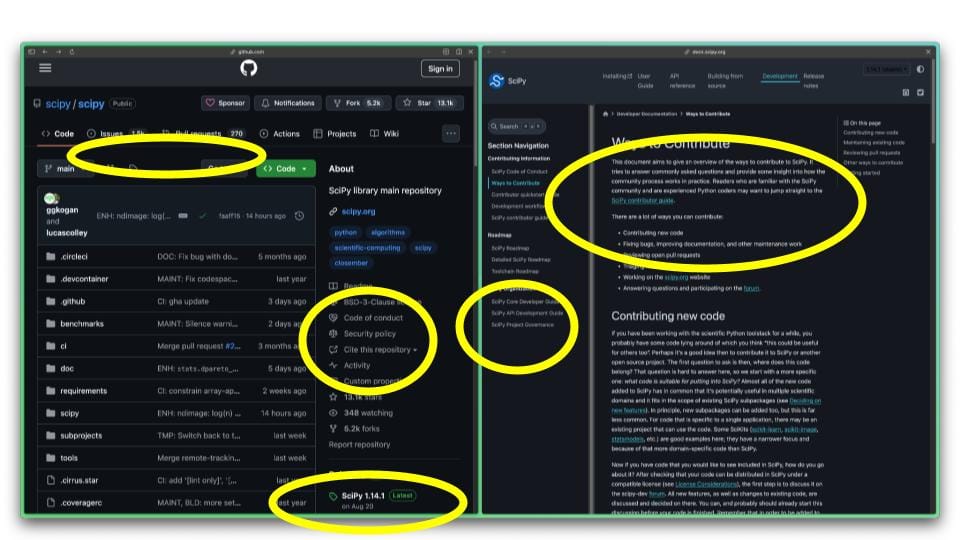
I would argue that an open-source software project is already a pretty good example of this [circled in yellow]; we have the infrastructure of the organization, we have a code of conduct, we have contribution guidelines, we have a variety of documentation about the organization itself, we have semantic versioning for releases, software licenses and more.
Today, I'm talking about how to move beyond something pretty well contained within code. I would argue that a GitHub repo or a GitHub organization combined with a little bit of extra-institutional wrapper, for example, a nonprofit fiscal sponsor like NumFocus, provides most of the core needs of an open-source project. And to the extent that there are gaps, people fill those gaps by instantiating private communication channels where they need them.
As I move into the rest of the talk, I am going to be talking about communities that are a lot more heterogeneous - more stakeholders, more diverse work products, more diverse working environments, which present challenges around infrastructure. This includes drawing insights from experience and open source software development, where I think best practices around managing contributions - using workflows like Git, establishing specific workflows for specific projects and specifying, say how one becomes a contributor with the authority to merge a pull request - are applicable, even as we move beyond the environment of managing code.
Conceptual Architecture for KOI
Practices, Algorithms, & World Models
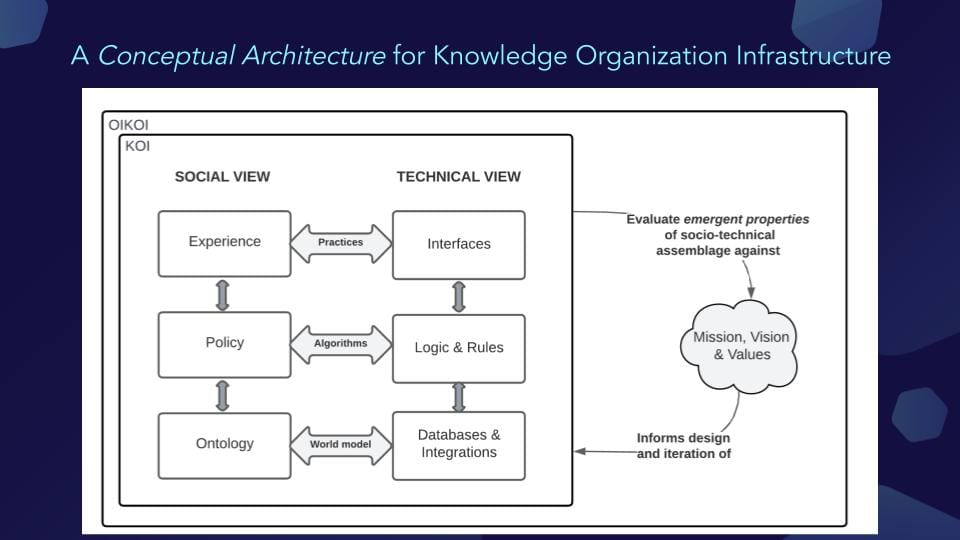
One way to think about the conceptual architecture is through layering. I like putting the social and the technical views side by side to view the overall system as being fundamentally human. This way, when I evaluate emergent properties of a socio-technical assemblage against mission, vision, and values, I am basically allowing for an intervention over the system itself. In the small box labeled KOI is a set of practices and technologies. Then, when you account for the organization and its governance processes, this is labeled OIKOI, which stands for Organizational Integrated Knowledge Organization Infrastructure, something of an inside joke based on the historical meaning.
Noun
oikos (plural oikoi)
(historical) A basic societal unit in Ancient Greece; a household or family line.
Etymology: From Ancient Greek οἶκος (oîkos).
In the KOI model, the social view shows an integrated system that incorporates the human, the entity, and the human governance processes, paired with the technical view/object, which contains any number of interfaces, logic and rules, databases and integrations, or various kinds of data stores ranging from literal databases to web platforms, air tables, google sheets.
When we look at this from a social perspective, the interfaces are where you produce the experiences, the logic and rules are where you embody policies, and the databases and integrations are where you entrench ontology. Basically, practices, algorithms, and world models.
As someone who comes from more of a robotics background, I am attuned to the fact that your world models are important grounding. Practically, you can not write an algorithm that tries to implement something that refers to a concept that does not exist in your ontology. And the algorithms are the things that often produce the circumstances or the incentives within which the practices emerge. This means that it's quite difficult to work from the top down. Instead, you really have to work from the bottom up, but you can run into issues here, too.
An important issue we are tackling with KOI is ensuring a degree of flexibility in the base level. This requires enough consistency to render these systems interoperable, computable, and stable enough that systems aren't breaking when you make changes but seeking still to preserve flexibility so that, to the extent possible, ontologies can emerge from practice and, therefore, better fit the communities they're serving, and adapt as those communities adapt, grow and change, fork and merge.
Interfaces: Organization + Environment
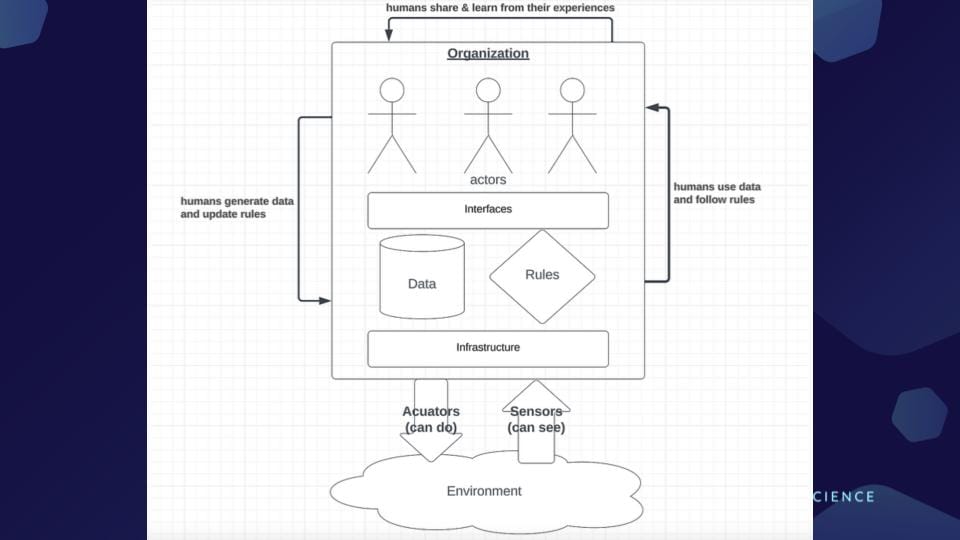
So the kinds of systems that we have been working on, they have roughly this shape. We have a group of actors within an organization interacting with the system through a set of interfaces. What they experience as a consequence of both data and rules and that technical infrastructure facilitates further action onto the world and reading sensing information from the world. And we see humans as both following following rules as well as potentially updating those rules and being able to interact directly with each other, sharing and learning from their experiences.
Multiple Instantantiations of Conceptual Architecture
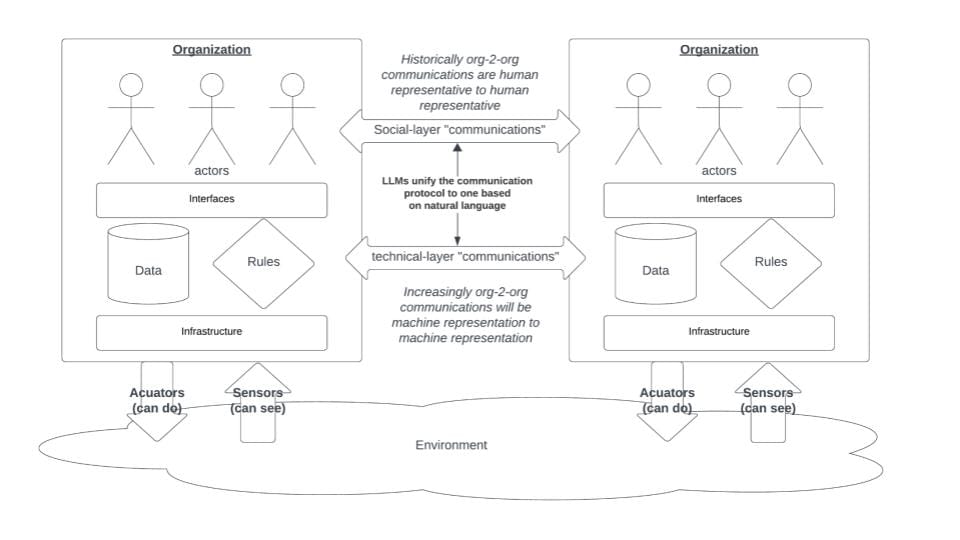
We are moving towards a model where we can have multiple instantiations of this conceptual architecture interacting. We see a lot of this at the social and technical levels.
You get social interoperability when you have common members of communities or discussions or negotiations - on a Zoom call or in a chat channel together - you can communicate human to human. At the technical communications layer, these are effectively data services. You open up an API, it has a specific set of queries that it will respond to, maybe it has an access control regime, but you can have technical communications.
Part of what we're seeing with the advent and the adoption of LLMs is a bit of mixing, where you could have a technical interface talking to a human or vice versa. And that opens up both opportunities and challenges. And some of what we will get to later are attempts to wield that capability in a careful and respectful way.
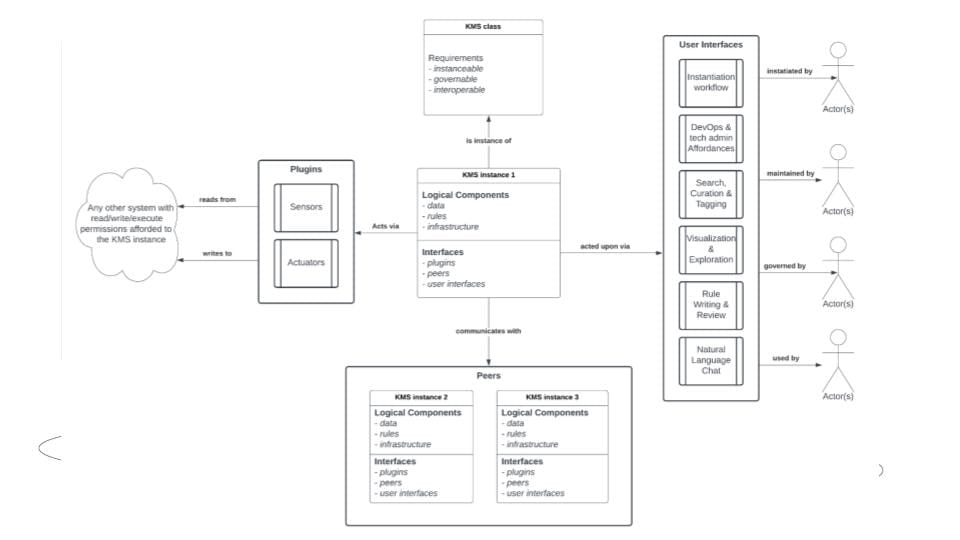
The technology that we've been developing has the goal of being instantiable, governable, and interoperable. We have three bespoke instances at this stage but we are moving in a direction where there will be software that's easier to pull and more realistic for someone to create their own instance. With the caveat that since most of what we're building is not actually software, it's glue for assembling things it can be a little bit tricky.
We're pretty excited about it, though, and we're looking at breaking these down, the interfaces by the different actors that would interact with those interfaces, going all the way from instantiation to the technical administration through the data governance tagging and curation through the discoverability, visualization and exploration, as well as writing rules and adjusting the internal policymaking within these systems and finally natural language chat interfaces. As you will see, when we get to the concrete examples, there's quite a bit to it, but we are focused on using out-of-the-box tools and combining them into interesting assemblages.
What is Knowledge Organization Infrastructure "made of"
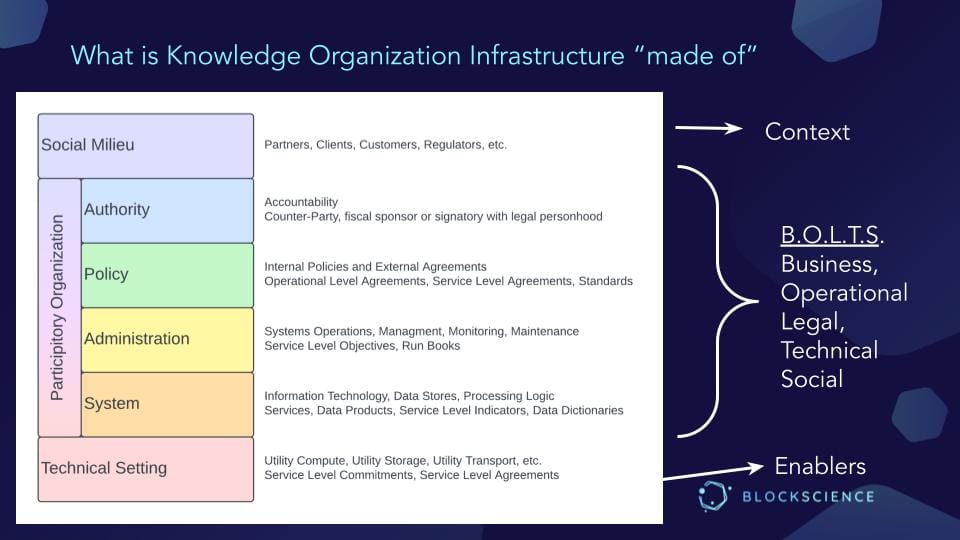
Social Milieu
Partners, Clients, Customers, Regulators etc
These kinds of systems do not exist outside of the human world, but they still have to have an acc0ountable party.
Authority
Accountability: Counter party, fiscal sponsor or signatory with legal personhood
Do you, as an entity, have the ability to write agreements, and make decisions? Who is responsible for the behavior of the system? Because anytime we get involved with developing software, data products or services, it is important to understand who is responsible, that these technologies are not in and of themselves separate from the humans that produce, operate, maintain, and use them. Authority is an entity.
At BlockScience we have things that we own and operate, Metagov as a legal entity nonprofit owns and operates things and in settings where projects themselves are too small to have their own entity you end up with a fiscal sponsor or some sort of signatory with legal personhood. At Metagov, we sponsor a variety of projects that are run by research directors. At NumFocus there a bunch of fiscally sponsored projects, so that even though there are individual actors running the project, there is still a legal accountability layer associated with the fiscal sponsor.
Policies
Internal policies and external agreements. Operational agreements, service agreements and standards
Policies is where we have licenses and other kinds of agreements. It could relate to what kinds of consents are required. This is where we actually enter agreements. So you have to have the authority to enter them in blue and then you enter them at the level in green.
Administration
Systems Operations, Management, Monitoring, Maintenance, Service level opbjevtices, Runbooks
The system admininstration layer. You might have a set of rules that say you're supposed to do certain things, but you actually have. Humans practices and technologies, say access control regimes that are used to actually implement those policies. And it's important because if the authority is accountable for living up to the agreements they make, and the policy represents the agreements that have been made, then the administration is the follow through on that.
System
Information technology, Data stores, Processing Logic Services, Data Products, Service level indicatios, Data Dictionaries
The system is the actual information technology. It's the data in the database, the files in the Google Drive, it is what you are actually interacting with. We may have a variety of documentation, technical documentation, data dictionaries, the API specifications, possibly service level indicators and other data about the system.
Technical Setting
Ultitily Compute, Utility Storage, Utility Transport etc. Service Level Agreements, Service Lvel Commitments
At the level below the Participatory Orgnanization we have the various technologies assembled to create the system, this includes storage, compute transport, and agreements with any of the entities that you are in fact consuming such services from.
Devil's in the Details: Gathering Requirements

So, how do we get from general to specifics? This comes in part from my work with the data trust, where we were trying to figure out, "Sure, the devil's in the details, but which details?" What do we care about?
What are
From Where?
This is a description of what phenomena the data is about and how it is being collected – it could be data from a platform such as github or google docs, a forum, a chat application, or a social network.
It turns out that we care about where the data is coming from. What is the phenomena of interest? What is it a measurement of? And how is it collected? Did it come from a chat application as a social network? Is it economic data? Is it GitHub, Google Docs, or something else?
From Whom?
This is a description of the people from whom the data is being collected – it could be members of a particular constituency, users of an app, or a specific demographic.
We are trying to clarify who this came from, their expectations, and what kinds of agreements they are party to. If the source is a forum, then it is more obvious who the authors are based on identity within that forum. But in other environments, it can be less obvious whose data it is. You often see clauses in user agreements for applications that say, "By using this, all your data is ours," which is not ideal, but it is the current state of the art in a lot of applications. I don't generally consider that a good model; it's legal but questionable.
For Whom?
This is the description of the people or entities expected to use the data –it could be the same people who contributed it, it could be researchers, the data stewards themselves, other researchers, companies, or nonprofits.
Continuing with the discussion of the kind of clickwrap, which tends to favor the parties collecting data, "we can use this for whatever we want," it seems more realistic, at least from an end-user perspective, to constrain the expected uses of data to defined purposes. Is it being used by researchers, data stewards, other researchers, companies, and non-profits? Is it medical data?
For What?
This describes what the data will be used for. EG. improved visibility for the workings of their community, research into governance modalities, improve medical care, to send advertisements, etc)And then we kind of switch into the.
Although it is not common to distinguish what collected data can/will be used for, data use can be specified, and it is more realistic to do so in smaller settings. So, in knowledge organization infrastructures, which are serving specific communities, where the members of the communities are the people the data is from, and to the extent that those communities and their partners are also the people who the data is going to, then there is more room for policies that specify data use.
And to the extent that you are a relationship with the entities that are managing that data - collecting it, using it, organizing it - you may be more willing to share data if you're confident that it will only be used for the things that you have agreed it can be used for.
Examples from Metagov's Knowledge Organization Infrastructure
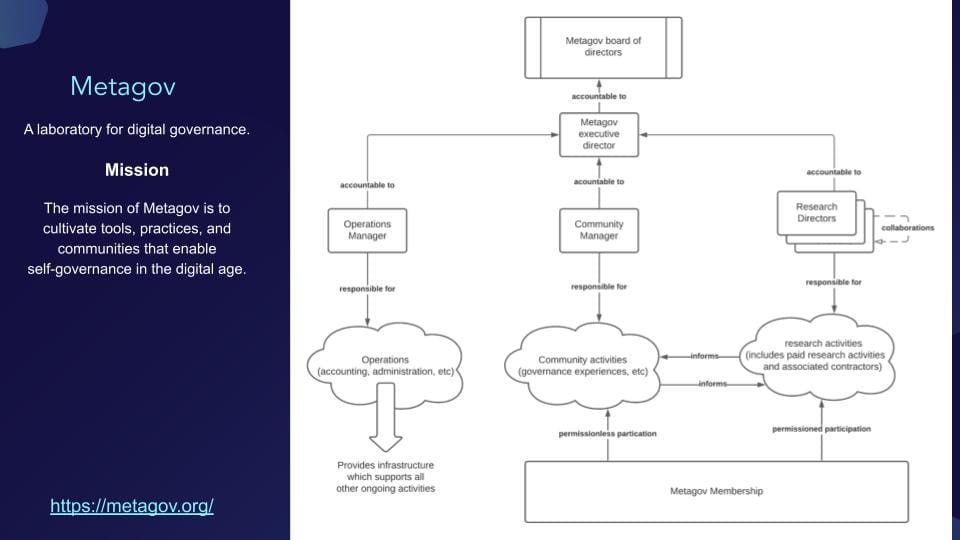
Metagov provides an operating context to discuss the challenges and opportunities of knowledge organization infrastructure.
- Metagov includes people from all over the world
- A mix of researchers, practitioners, and leaders of other organizations
- Diverse experiences and opinions
- Great collaborations, but also debates & arguments
- Website, Seminar, and Public Slack are primary access points
- Extensive discussions in public channels can be a bit meandering
- Discussions in private channels can be opaque
- Project work is both curated and emergent
- Research directors are nominated and approved but then are highly autonomous in their research projects
- They secure funding from government and philanthropic grants
- As a member, it is hard to keep track of the project portfolio, to know what one can contribute to, and how
Metagov shares some aspects in common with open-source projects, but without the locus of coordination in the form of a GitHub organization or repo - Metagov is a lot more spread out. The following knowledge tools and architectures are elements of Metagov's Knowledge Organisation Infrastructure.
GovBase
Policy: Creative Commons. Point of Contact: Josh Tan
Administration: Working Group in Metagov slack. Airtable built in Access Control
System: Airtable instance

From where?
Manual data entry and/or import from researchers spreadsheets or local data stores
From whom?
Researchers within the metagov community running various research programs ranging from collecting and collating data from online communities public documentation to running surveys
For whom?
Researchers both inside and outside of the metagov community that are interested
For What?
1. Primary use case is making data used in various publications “open source” so that readers of various blogs and academic papers can find the relevant source data
2. Secondary use case is discovery of interesting synergies between the various data sets and ideally foster new research based on that data
3. Eventually to be integrated as a data source into Metagov KOI-pond (but improved quality control is required)
In the beginning, when it was a small group with only a few data sets, it was stewarded pretty well. However, anyone who has tried to manage a database using a non-database technology quickly realizes it can get out of control. GovBase, as an example of knowledge organization infrastructure, was both very effective and eventually hard to govern, so it may be better suited to stewarding data in other infrastructures.
Metagov Members Directory
Policy: Opt-in. Public
Administration: Community Manager (curation). Website Developer(publication)
System: Onboarding Typeform. Private dataset. Website
Another curated data set in Metagov is the member's directory, primarily managed by a community manager, pushed to the website via web developer. It is part of the onboarding process. A community manager will direct them to an onboarding-type form; they fill out what they're interested in and decide how much information to share about themselves. There is both a private version of the data set, and there's a curated public version on the website where you scroll through and click on people's LinkedIn if they have chosen to share or see information about their other affiliations.
Telescope
Policy: RMIT University Institutional Review Board (IRB). Consent Required, Anonymization Optional, Point of Contact: Ellie Rennie
Administration: Participatory message flagging, Authors consent via bot, Ethnographers curate and interpret
System: Discord Bot (in server being studied), Discord Server (for ethnographers), Private Database (under IRB)
Telescope, a homegrown knowledge organization infrastructure, was initially developed under a grant secured by Dr. Ellie Renny, a professor focused on automation and society at RMIT.
Developed to be consistent with her Institutional Review Board (IRB), it is a set of bots that allow you - if researching a predominantly online community - to give them an emoji telescope that will flag a message as being important. That triggers a flow where the person who wrote the message gets a consent request, and the ethnographers get a curation flow that helps build a dataset partially developed by the community.
Community members online can participate in the process of determining what's important and organizing it for use by the ethnographers, who would, in turn, provide feedback, guidance, and research papers. A project called Sourcecred included Telescope as a Discord bot, and today, there is also a Slack version.
Abstract: In the CredSperiment, participants were compensated based on their contributions within a permissionless organization using their developed SourceCred software. Contributors to SourceCred accepted payment based on sophisticated calculations called “Cred scores.” This ethnography of the CredSperiment examines its significance as an early attempt at instituting a regenerative economy. Drawing on Kealey and Rickett’s (2014) concept of contribution goods, the ethnography explores how a specific community can define what it values through its day-to-day actions, potentially overcoming plutocratic governance in web3 systems. The CredSperiment also exposed the challenges of permissionless systems, including perceptions of extractive behaviors. The article suggests that web3 requires machine-assisted governance with community inputs - terraforming as opposed to environmentally - if the benefits of permissionless systems are to be realized.
Project Cards
Policy: Research Directors are required to write public project cards.
Administration: Project Manager coordinates. Research Director group meetings. Website update rules
System: Website. Project channels in Slack. Zoom meetings

Another basic piece of knowledge organization is project cards, which are project documentation. On the Metagov website, there are a variety of public project cards that our research directors are theoretically required to write, increasingly supported by a project manager who helps ensure they get generated. The social pressure happens in the research directors' group meeting, and ultimately, the pushed content has to be added by the web developer.
There's a lot of room for automation here, but for the time being, they are pretty simple: filling out a schema and ensuring you answer a specific set of questions, provide an image, and upload. The practical system here is the website, the project Slack channels, the Zoom meetings, and any Google Docs and content, but the content from the projects themselves is spread pretty wide, and we are not trying to aggregate or reproduce it.
Curated Papers & Blogs
Policy: Public Documents only. Authored by metagov members
Administration: Working group (curation. Software developer (ingestion)
System: Google sheet with metadata. Referenced documents. RID database records. Vectorstore embeddings
A working group in Slack fills in a Google sheet, capturing the title, authors, URL, and some metadata. Then, a checkbox on the left determines whether something has been brought into a database. Because the Google sheet is more of an interface - not the core data - it refers to things and says, "This belongs in our data set." We can have vector embeddings for use with LLMs. We are implementing the RID database, a graph database that you can think of as a knowledge graph but where the nodes in the knowledge graph are knowledge objects.
Reference Identifiers
Policy: MIT License. Beneficent Dictator
Administration: Working group peer review. Weekly Standup
System: Github repo. Python code. Neo4j graph databases. Plugins (eg slack, github, google docs, etc)
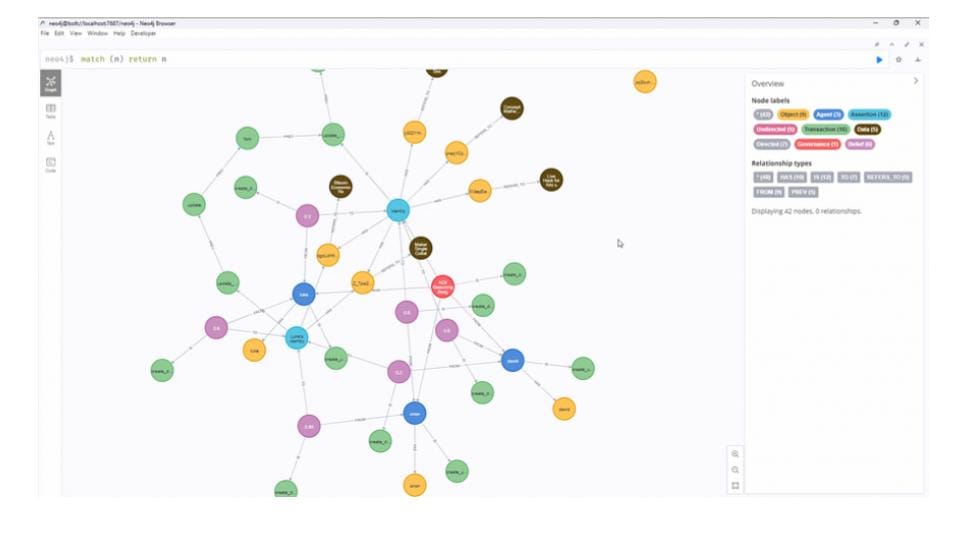
Reference identifiers are a piece of Python code that connects with Neo4j graph databases. It was developed at BlockScience and is under an MIT license. It is primarily Beneficent Dictator, with Luke, the main developer, guiding development with contributions and peer reviews from other working group members. There is a weekly standup and a GitHub repo with Python code and the material for developing graph databases.
The most important part here, though, is plugins. We need to get the nodes automatically and do not want to build these things from scratch. So you can curate at the graph database level, but you want to be scraping the content. And that ties back to the above element - Curated Papers & Blogs - where if the Google sheet is a knowledge object that we know about, then we can run a process that says, "Go get all of these things and create nodes for them" as well as create a vector store embeddings for them.
KOI Pond & Demo
KOI Pond is the exciting thing here: organizing all these different knowledge organization tools into a coherent system that supports the accessibility and discoverability of Metagov's local knowledge.
Knowledge networks that can outcompete large institutions -especially w/regard to #innovation - can only emerge from collaborative coordination between peers. Thank you @ElinorRennie & @metagov_project for helping bridge the gap between today's tech & future ways of collaborating https://t.co/D8CTWSUFK1
— BlockScience (@block_science) May 2, 2024
Abstract: Knowledge Organization Infrastructure (KOI) is the architecture and implementation of a shared digital space, including but not limited to chats, forums, wikis, spreadsheets, document databases, and machine learning (ML) applications such as recommendation engines or large language models (LLM). Communities of practice rely on shared spaces to accumulate and share learnings, as well as to develop and maintain trusted relationships with other practitioners in a non-transactional setting. Digitalization has led to mass privatization of social infrastructure, which was historically self-organized within a community rather than outsourced to a platform. The associated reduction of variety in KOI has led to a one-size-fits-none model and accelerated rather than ameliorated the ongoing loss of social cohesion. Leveraging a theory of Technologies as Social Practice and an increasingly modular and interoperable set of open-source KOI components, we are providing technical tools and organizational practices for communities of practice to self-provision and self-govern their own KOI. Our hypothesis is two-fold: (i) the expertise required for and the attentional cost of provisioning and governing a locally fit-for-purpose KOI can be significantly reduced and (ii) a locally fit-for-purpose KOI will significantly improve the experience of participating in a community of practice.

Because Metagov's organizational knowledge is pretty opaque and spread out, with everybody working in their own place, we want to get to a point where you have User Interfaces like the chatbot; you have search interfaces and other applications that you can build hit these things via APIs. For that, we have the VectorStore embeddings, the graph database, search, and LLM inference via third-party APIs.
Then, the actual actuators and sensors are bespoke, and we have been talking about them; the systems I just shared with you are the potential, current, and future data sources that we gather from. And the actuators (at present) are primarily the chatbot. Not that the chatbot is the end goal, it is just the thing that people like to interact with.
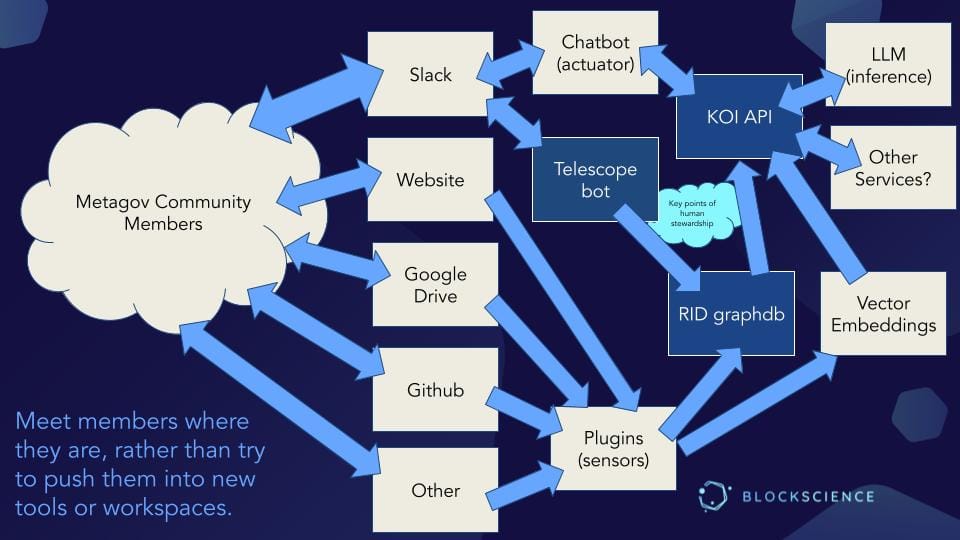
We have a number of data sources - Slack, Website, Google Drive, Guthub, Airtable, and others - and we want to meet the members where they are rather than push them into new tools or workspaces.
We can connect our plugins (Sensors) and run services that write to the RID graph database, and the vector embeddings and the KOI API effectively orchestrates this. This includes the ability to invoke the LLM inference and, potentially, other services in the future. Most people then interact with this information directly via a chatbot (Actuator) in Slack, which is also a data source.
For managing consent, we have an instance of the telescope bot. So if your Slack data is being telescoped and gathered, it is not automatically done without you knowing about it. You get a direct message asking for your consent with the option to anonymize. And so this is an example of a slightly more structured flow where we are trying to be very explicit about what people are and are not contributing and what they are and are not consenting to.
This is important, especially in a space like Slack, where people are just having conversations, and it is unclear that they want everything they say to be surveilled. Thus, creating a mechanism through which conversations can be consent-filtered and toned down gives people more confidence in the system.
There is also an interesting phenomenon that this system feeds back on itself because the chatbot acts in Slack, and Slack is sensed, so it sees its own past. We have not figured out how to study that yet, but it is an interesting and important factor that we do not really know the consequences of yet.
NPC Day Denver: KOI Demo
About BlockScience
BlockScience® is a complex systems engineering, R&D, and analytics firm. By integrating ethnography, applied mathematics, and computational science, we analyze and design safe and resilient socio-technical systems. With deep expertise in Market Design, Distributed Systems, and AI, we provide engineering, design, and analytics services to a wide range of clients including for-profit, non-profit, academic, and government organizations.
,
