

By David Sisson and Ilan Ben-Meir

In a documentary released in 1990, Steve Jobs tells a story that he would return to repeatedly over the course of his career:
I think one of the things that really separates us from the high primates is that we’re tool builders. I read a study that measured the efficiency of locomotion for various species on the planet. The condor used the least energy to move a kilometer — and humans came in with a rather unimpressive showing, about a third of the way down the list. It was not too proud a showing for the crown of creation. So, that didn’t look so good. But, then somebody at Scientific American had the insight to test the efficiency of locomotion for a man on a bicycle. And, a man on a bicycle, a human on a bicycle, blew the condor away, completely off the top of the charts. And that’s what a computer is to me. What a computer is to me is it’s the most remarkable tool that we’ve ever come up with, and it’s the equivalent of a bicycle for our minds.¹
Conceptualizing computers in this way offers a beneficial reminder that they are ultimately tools, no matter how advanced their capabilities may be: At the most basic level, a computer is a machine used to process data. While beginning at this level of analysis might initially seem overly simplistic, doing so makes it possible to offer an account of how computers and associated tools (i.e., Information Technology) have evolved, in terms that make clear what the next stages in that evolutionary process are likely to be.
Fundamentally, a computer is hardware that is able to process data by following instructions — which requires memory to store instruction sets (algorithms) and data (the system’s state), and a processor that deterministically mutates the system’s state by executing instructions according to its programming. The user experience of interacting with nothing more than a box containing memory and a processor, however, is relatively poor, so a local operating system (such as Linux, macOS, or Windows) is usually layered over the hardware; users interface with this operating system, while the operating system interfaces with the computer’s hardware. At this level of complexity, a computer is generally most useful at assisting a single individual with creating and manipulating content, including (static) text files, rich text files, static pictures, motion pictures, (dynamic) spreadsheets, and applications (which one can think of as carefully curated packages of related instruction sets that together serve a useful function).
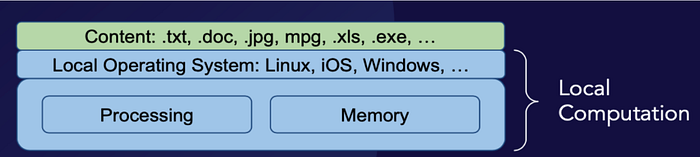
Local computation offers a host of benefits to users — but these benefits are generally limited to the individual scale: A person with a computer will almost certainly be able to work more quickly and efficiently than a person attempting the same work without the array of affordances that a computer offers.
The scale of affordances moves beyond the individual, however, when multiple local computers are connected to a network. A network of computers consists of local computers that are connected by hardware with the ability to transfer data between them. Connecting computers into a network makes it possible for multiple individuals to work on the same project at the same time, each using a different computer — or for a single individual to distribute their work on a given project across multiple machines. In today’s world, most computers are designed with the expectation that they will be connected to at least one network: the Internet.
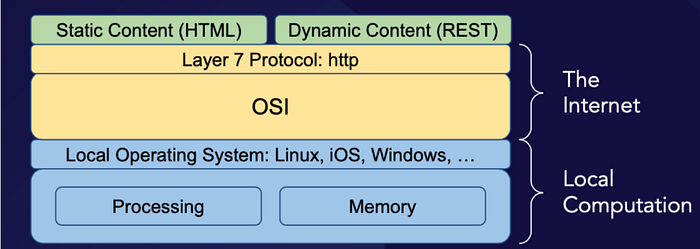
Through Tim Berners-Lee’s work developing and combining HTTP, HTML, and URLs, a network of computers provides the infrastructure for the World Wide Web — everything from static web pages to dynamic content (including the now-ubiquitous REST API, which allows one local computer to use “post requests” to instruct another local computer run a job, followed by “get requests” to retrieve its results.
In order for computers to meaningfully exchange data across a network, however, such exchanges must take place in a language common to all participants — which is to say, all of the components of a given network must participate in an overarching network architecture that structures the relationships between them. In the case of the Internet, this network architecture is formally conceptualized by the seven-layer Open Systems Interconnection (OSI) model developed by the International Standards Organization in 1984, and actually implemented by the four-layer Transmission Control Protocol/Internet Protocol (TCP/IP) model developed for ARPANET. Unsurprisingly, the TCP/IP model actually predates the OSI model; developing a concept from the bottom up, rather than the top down, is one of the best ways to keep abstractions grounded in reality.
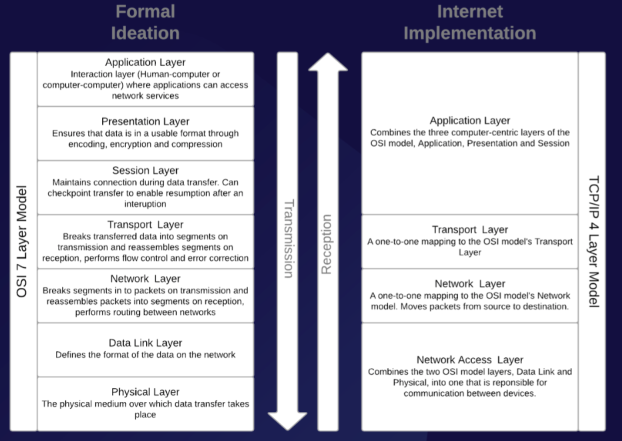
In both models, each layer represents a group of related functions involved in the sending and receiving of data across a network; furthermore, each layer operates on data provided to it by the layer below it, and provides data to the layer above it for that layer to operate on, in turn.
The topmost layer of the OSI model is the Application Layer, where “protocols […] directly serve the end user by providing the distributed information service appropriate to an application, to its management, and to system management [… including] those functions required to initiate, maintain, terminate, and record data concerning the establishment of connections for data transfer among application processes.”² The Application Layer is the layer at which the human-computer and computer-computer interactions involved in accessing network services take place. The next layer down is the Presentation Layer, which provides “the set of services which may be selected by the Application Layer to enable it to interpret the meaning of the data exchanged. These services are for the management of the entry, exchange, display, and control of structured data.” Through encoding, encryption, and compression, the functions that make up the Presentation Layer ensure ensure that the data accessed by the Application Layer is in a useable format, such that “applications in an Open Systems Interconnection environment can communicate without unacceptable costs in interface variability, transformations, or application modification.”
Underneath the Presentation Layer is the Session Layer, which serves “to bind/unbind distributed activities into a logical relationship that controls the data exchange with respect to synchronization and structure” in order “to assist in the support of the interactions between cooperating presentation entities.” The Session Layer maintains the connection to the network during data transfer, and can “checkpoint” a transfer to enable it to resume following an interruption.
The topmost layer of the TCP/IP model combines these three computer-centric layers of the OSI model — the Application, Presentation, and Session Layers — into a single layer, which it calls the Application Layer. In both models, the next layer down is the Transport Layer, which provides “a universal transport service in association with the underlying services provided by the lower layers [… and] transparent transfer of data between session entities.” The Transport Layer breaks transferred data down into segments on transmission, and reassembles these segments on reception; it is also responsible for flow control and error correction during these processes. The layer below the Transport Layer is also the same for both models; in each, the Network Layer “provides functional and procedural means to exchange network service data units between two transport entities over a network connection” by breaking down the segments of data produced by the Transport Layer into packets on transmission, and reassembling these packets into segments on reception. The Network Layer is also responsible for routing data between networks, and moving packets from their source to their destination.
The bottommost layer of the TCP/IP model is the Network Access Layer, which is responsible for communication between devices. In the OSI model, this Network Access Layer is divided into two distinct layers: the Data Link Layer, which is immediately below the Network Layer, and the Physical Layer, which is found below the Data Link Layer at the very bottom of the OSI model. The Data Link Layer works “to provide the functional and procedural means to establish, maintain, and release data links between network entities” by defining the format of the data on the network. Finally, the Physical Layer “provides mechanical, electrical, functional, and procedural characteristics to establish, maintain, and release physical connections (e.g., data circuits) between data link entities,” and consists of the physical materials over which data transfer takes place.
Taken together, the OSI and TCP/IP models are largely responsible for the architecture of the Internet — or at least, the architecture of the Internet as it has existed thus far. In a 1999 interview with Wired, Tim Berners-Lee agreed that it was “pretty much” correct to call him “the inventor of the World Wide Web,” because “I basically wrote the code and the specs and documentation for how the client and server talked to each other.”³ Historically, in a given conversation between two computers on the Internet, it has generally been the case that one computer operates as the client (that is, the party in the exchange making requests for data), and the other as the server (either by serving some HTML to the client, or by running a job and returning the results as per the client’s instructions). At a first approximation, such conversations always take place between two computers, and the mode of conversation is stateless — the protocol exists only in the here and now, and any knowledge of the past or predictions about the future are local to the individual local computers participating in the exchange.
With the advent of Web3, however, these conditions no longer necessarily apply. In Web2, the Application Layer of the OSI model relied largely on HTTP and other stateless, client-server protocols, but Web3 replaces these with peer-to-peer protocols such as libp2p in the same structural position — and this development, along with stateful consensus protocols, have made it possible for a network of computers to cooperate as if they were a single state machine: a network computer.
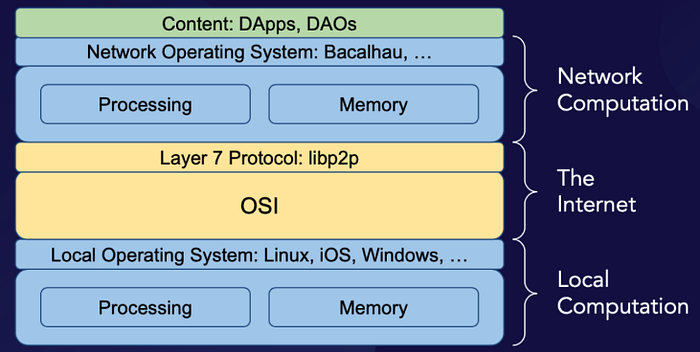
Due to this ability to achieve consensus regarding machine state, one can think of a network computer as a network of computers with something perhaps akin to self-awareness that enables the coordination and synthesis of the operations of its parts. (Note that “self-awareness,” here, is not meant to suggest actual sentience, so much as the possession of a persistent mutable state that is knowable to the entity possessing it, but only imperfectly expressible to others). In a network of computers, one local computer connected to the network might download a dataset, while another local computer connected to the same network performs analysis on a different data set; once both processes have finished, the first data set will be stored in the memory of the first local computer, while the results of the analysis of the second will be stored in the memory of the second. If instead the two local computers in question were both part of the same network computer, however, then once both processes have finished, the first data set and the results of the analysis of the second data set will both be stored in the memory of the network computer. If the exchange between two local computers connected to the same network of computers is akin to a conversation, then the operation of a network computer refashions that conversation into the form of an internal monologue; the local computers in a network of computers can hear only what the other computers in their network say “out loud,” while a network computer is both cognizant of and able to coordinate the “private thoughts” of the local computers that it links together, as well. In essence, a network computer organizes the cooperation of a network of computers into the structure of a local computer, but at a super-individual (that is, organizational) scale.
One crucial implication of this shift is that network computers are systems capable of receiving and modifying their behavior based on feedback, while a network of computers is, in itself, entirely a feed-forward system. Because it has its own memory, a network computer can maintain a persistent internal representation or model of the external environment, which the network computer can also persistently update in response to its previous computations — including by updating its own active instruction sets. Once a network computer has downloaded a data set, for example, it can analyze that data set and then adjust its future behavior on the basis of that analysis. A network computer can be understood as a network of computers that has the capacity to “learn” from the exchanges of data which take place across it — or as a decentralized computer instance with the capacity to translate the data that it “discusses with itself” into contextually-meaningful knowledge.
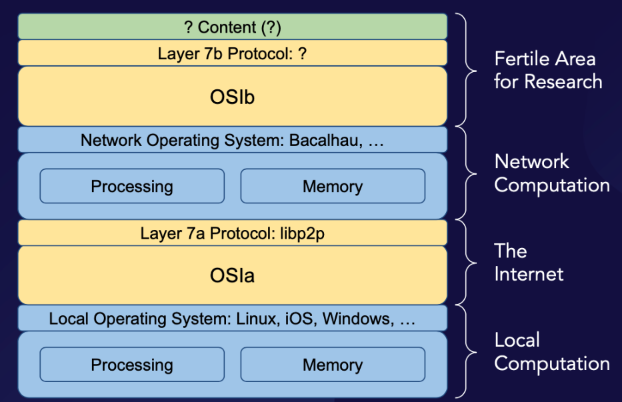
If a network computer is essentially a single computer instance distributed across multiple distinct machines, then it seems self-evident that the next major step in the evolution of computing will be to develop networks of network computers — but such networks will require new forms of network infrastructure. The OSI model was sufficient to enable the development of network computers, but our understanding of network architecture must be revised before it can adequately address the specific challenges involved in connecting network computers in order to create a broader network of network computers. To that end, it will be necessary to develop a new network architecture — call it OSIb — to organize and standardize the interconnection of network computers in the same way that the original OSI — which we will hereafter refer to as OSIa — organized and standardized the interconnection of local computers.
If network computers make it possible for networks of computers to “learn,” and networks of computers make it possible for local computers to exchange data about their internal operations, then a network of network computers would make it possible for the network computers that comprise it to exchange data in the form of concepts, or what we might call knowledge-data (to remind us that its identification with knowledge is ultimately only an anthropomorphic metaphor, along the same lines as our previous mentions of computers conversing, learning, and thinking). Each network computer in the network could learn from what the other network computers in the network have learned. For example, imagine that a user asks Alexa to tell a unique bedtime story tailored to his specific interests. In today’s world, Alexa might instruct ChatGPT to write such a story based on its past interactions with the user — but because of the stateless nature of the network connecting them, all of the detailed knowledge of the user’s individual preferences would have to be shared in clear text with both Amazon (Alexa) and OpenAI (ChatGPT) — which is closely partnered with Microsoft — along with the generated story. A network of network computers, on the other hand, would make it possible for network computers to develop models that are as good as or better than (and way more contextually relevant) than the models powering Alexa and ChatGPT, simply by sharing model weights through decentralized federated machine learning. This would enable both the request for the bedtime story and that story’s generation to be handled locally, without the need for the user’s personal information to be transmitted through the network.
In effect, such a network of network computers would transform each network computer involved into a complex array of sensors capable of inferring and presenting its own perspective on reality — which is to say, its own internal model of the external environment — to all the other network computers in its network, and which could then integrate this array of perspectives into its own internal representation of the external environment. One might imagine an updated version of the story of the blind men and the elephant: Five network computers may each be able to identify the specific part of a knowledge-elephant that they are locally able to sense, but it is only by networking the five computers together that any one of them is able to identify that these parts are each also smaller parts of a larger unified whole. By making it possible for network computers to communicate the internal representations that they maintain to other network computers, a network of network computers would enable each network computer’s internal representation to increase its accuracy or its generality through a decentralized federated machine learning mechanism. Each network computer would still have its own unique internal representation of the external environment; a second-order network computer would be required to arrive at cross-network consensus representation, but a third-order state machine — a “network of network computers computer” — will remain thinkable only in theoretical terms, at least until a working implementation of OSIb has both been developed, and had time to mature.
The Internet, as it exists, is a marvel of human ingenuity — but it was not designed for computations with this level of complexity. What might a network architecture that is up to the task look like? OSIa provides a compelling foundation for formal ideation, which we can build upon in order to begin answering the conceptual questions involved — but what would an actual implementation of OSIb look like?
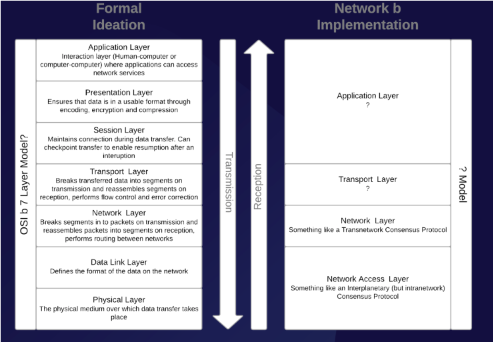
This is a fertile area for further research, but we can offer some informed speculation. At the Network Access Layer, we might find something like the Interplanetary Consensus Protocol employed by the Filecoin network, which was built around the primary design goal of horizontal scalability — call it the Intranetwork Consensus Protocol. The ICP has many of the properties of a local area network, however — what sort of protocol(s) would be needed for a wider-area network? What would the transport protocols be, and how might we develop something like a Transnetwork Consensus Protocol to facilitate the difficult job of aligning concepts (knowledge) across different organizations that “think” in different conceptual and computational languages and idioms? What would the Application Layer look like?
One way to approach these questions is through the idea that the purpose of this second-order Internet would be to communicate knowledge about concepts (and the relationships between them) derived from the shared states of the network computers participating in the broader network, which are in turn derived from the data and information communicated between local computers connected to the first-order Internet. For an analogy, we might think about the structure of the human brain.⁴
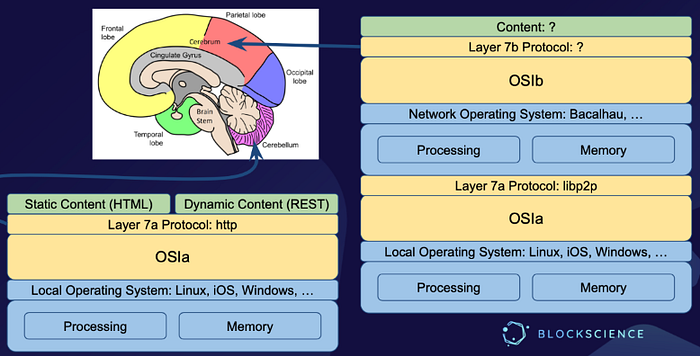
The cerebellum is like a network of computers — it has a homogenous modular architecture, and exclusively feed-forward processing. By contrast, the cerebrum functions like a network of network computers — the frontal, temporal, parietal, and occipital lobes — each of which has its own heterogenous area architecture, and all of which are capable of both feedback and feed-forward processing.
One might also approach these questions through the framework of Stafford Beer’s “Viable System Model,” which is central to the school of thought known as cybernetics. As Michael Zargham and Kelsie Nabben explain in “Aligning ‘Decentralized Autonomous Organization’ to Precedents in Cybernetics”:
The Viable System Model (VSM) is a representation of the organizing structure of an autonomous [that is, self-governing] system which is capable of adapting to changes in its environment, in line with its purpose. […] The VSM is comprised of five systems which co-regulate the organization at different scales in time, and different spatial scales encompassing the various critical functions of the organization. […] Each System of the VSM from 1 to 5 operates on a progressively slower natural timescale. Systems 1 and 2 rely on consistency from System 3, but Systems 4 and 5 must have the capacity to adjust System 3. Beer compares this model to human decision-making by suggesting that Systems 1–3 are like the autonomic nervous system, System 4 is like cognition and conversation, and System 5 can be related to conscious reasoning and decision-making.⁵
In short, VSM seeks to explain an entity’s operations (O) in the context of its management (M) and its interactions with its environment (E).
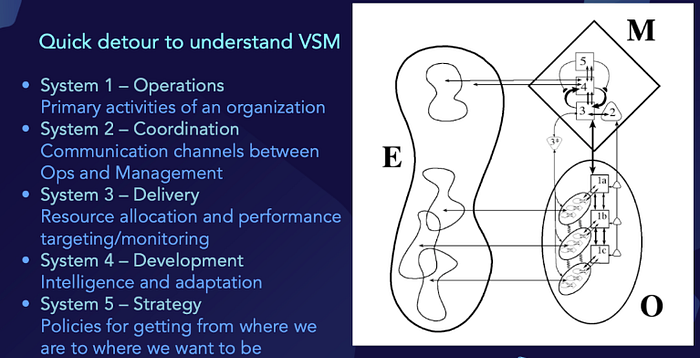
In System 1, each unit is itself a viable system, due to the recursive nature of Beer’s model. System 2 represents the information channels and bodies that allow the primary activities in System 1 to communicate with each other, and that (therefore) enable System 3 to monitor and coordinate the activities within System 1; it is what one might think of as the scheduling function of shared resources to be used by System 1. System 3 represents the “big picture view” of the processes inside of System 1 — the structures and controls that are put into place to establish the rules, resources, rights and responsibilities of System 1, and to provide an interface with Systems 4 and 5. System 4 is made up of bodies that are responsible for looking outwards to the environment to monitor how the organization needs to adapt to remain viable. Finally, System 5 is responsible for balancing demands from different parts of the organization in order to steer policy decisions concerning the operation of the organization as a whole.
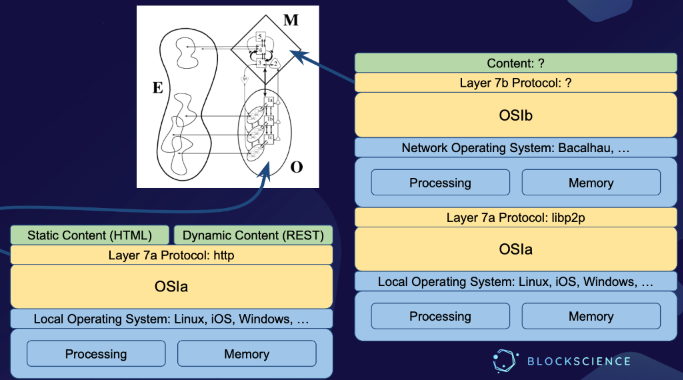
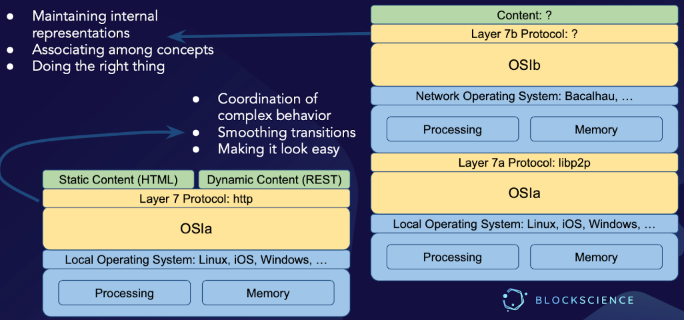
In short, the development of OSIb will make it possible for the networks of local computers that OSIa enables us to construct to function not as endpoints unto themselves, but rather to serve as the conduit for the basic sensors and actuators that make up those http endpoints — System 1 — into a much larger and more complex system, the purpose of which is to make both tactical and strategic sense of sensor inputs, in order to derive actuator control signals that are likely to drive desired outcomes.
If the history of human beings has demonstrated anything, it is that it is a profound evolutionary advantage to be able to construct and share internal representations of the world that are stable at the first approximation — that the ability to share knowledge, beyond the simple exchange of data, significantly improves one’s ability both to make well-founded decisions and to evaluate their outcomes. Feed-forward circuits like the client-server model of the Internet cannot share knowledge in this way, because they lack the coherent and consistent internality that is requisite for the kind of contextualized self-reflection that connects discrete instances of thinking into a trajectory toward greater knowledge.
The Internet as it has existed is the only tool that we currently have that comes close to working at the scale at which the world of tomorrow will be built, but as an exclusively feed-forward circuit, it is simply not yet up to the task. The control of any feed-forward system must necessarily come from outside that system, as feed-forward systems lack the infrastructure for meaningful autonomy. This control can come from foreign institutions, or it can come from native second-order cybernetic systems. The first option ultimately leads to a situation in which local computers give us instructions about how we are to think about our environment; the second, a future where our network computers teach us new ways we can learn about the world in which we live.
Footnotes
[1] Memory & Imagination: New Pathways to the Library of Congress, directed by Julian Krainin and Michael R. Lawrence (1990). https://www.youtube.com/watch?v=ob_GX50Za6c&t=24s.
[2] Zimmermann, Hubert. “OSI Reference Model — The ISO Model of Architecture for Open Systems Interconnection.” IEEE Trans. Communication (USA) vol. COM-28, no. 4 (1980): 430.
[3] Oakes, Chris. “Interview With the Web’s Creator,” Wired. Published 10/23/1999, accessed 5/1/2023, https://www.wired.com/1999/10/interview-with-the-webs-creator/.
[4] Medina, J.F. and Mauk, M.D. “Computer Simulation of Cerebellar Information Processing.” Nature Neuroscience, vol. 3 (November 2000): 1205–1211, doi: 10.1038/81486.
[5] Zargham, Michael and Nabben, Kelsie, Aligning ‘Decentralized Autonomous Organization’ to Precedents in Cybernetics (April 4, 2022): 4–5. Available at SSRN: https://ssrn.com/abstract=4077358 or http://dx.doi.org/10.2139/ssrn.4077358
Cite as: Sisson, D., Ben-Meir, I., 2023. “From Networks of Computers to Network Computers — and Beyond”. BlockScience Medium (blog). Available online: [insert link]
Special thanks to Michael Zargham for input and edits and Jessica Zartler for editing and publication.
About BlockScience
BlockScience® is a complex systems engineering, R&D, and analytics firm. By integrating ethnography, applied mathematics, and computational science, we analyze and design safe and resilient socio-technical systems. With deep expertise in Market Design, Distributed Systems, and AI, we provide engineering, design, and analytics services to a wide range of clients including for-profit, non-profit, academic, and government organizations.
