
ML Pipeline Progress & New Success Metrics
This article is an update to the Gitcoin community about the results of the GitcoinDAO Fraud Detection & Defense (FDD) working group, and the results of the Anti-Fraud machine learning pipeline from Gitcoin Round 12..
Background
The Gitcoin ecosystem continues to see rapid growth in its quadratic funding program for Ethereum public goods, more than tripling its match funding from $965k in Round 11 at the end of September, to $3.3 million in Round 12 in December. As funding increases, the draw for potential Sybil attackers becomes more lucrative. The Gitcoin DAO Fraud Detection & Defense working group must continue to remain agile, iterating on and integrating the learnings from each round in analyzing the data from the machine learning pipeline and feedback from human evaluators.
Building on work in Round 11, the BlockScience team employed new data science tactics and continued to “train” the ML algorithm to flag possible Sybil attackers, while “learning” from the human evaluators. During round 12, we continued to work on documentation and training with the Gitcoin DAO Development Operations team to enable the DAO to take over running the ML pipeline. BlockScience, together with the FDD working group and Gitcoin Stewards, also reflected on key metrics to continue to improve analyses of the results to provide the best insights to inform policy making by the Gitcoin DAO.
What’s New This Round
The BlockScience team focused much of their efforts this round on codebase improvements and documentation updates, to ensure a mature and stable environment for increased numbers of collaborators and increasing scale of data throughput from the continuing growth of Gitcoin rounds and Sybil incidences.
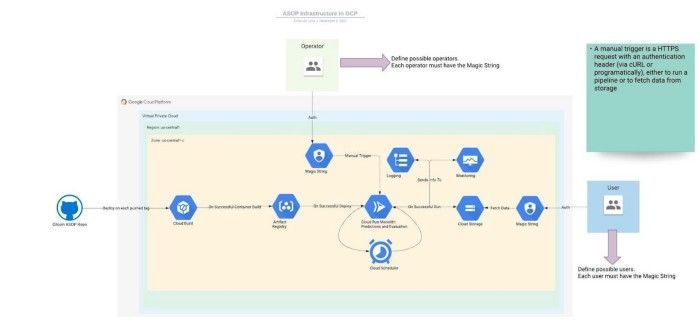
The Anti-Sybil Operationalized Process (ASOP) pipeline exists entirely on cloud infrastructure, with traceable data provenance through every step for access-controlled users. Several BlockScience researchers presented on the current architecture of the FDD micro-services at the GR12 Hackathon, which you can watch here for more details.
Another significant change this round was the move away from the ‘Fraud Tax’ as a main metric of the FDD workstream. This metric was used to estimate the amount of matching funds that went to fraudulent contributions that would otherwise have gone to legitimate grants. In previous rounds this was paid out by Gitcoin Holdings at their own expense, in the interest of ensuring legitimate grants were not shortchanged by fraud that occurred outside of their control. However, on further community discussion it was noted that paying the Fraud Tax was essentially subsidizing fraudulent matching via Sybil attacks. Therefore in GR11, the Gitcoin Stewards voted not to pay out the Fraud Tax.
Rather than the Fraud Tax, in Round 12 we defined a new metric for assessing rounds — the Flagging Efficiency Estimate. This metric estimates the percentage efficiency of the overall ASOP process at detecting Sybil accounts, to determine how accurately these combined processes are able to identify false users. Next we will examine the results of GR12 in light of these new metrics.
Round 12 Results
In this last round (December 1–16), we evaluated more data than ever before, analyzing information from nearly 29,000 Gitcoin platform users. Our main weapon in the fraud defense arsenal — the ML algorithm — is “tuned” by BlockScience with input from a dedicated team of Gitcoin stewards and reviewed by human evaluators. In previous rounds we explored various aggressiveness levels — tuning between sensitivity and specificity to balance between identifying potential Sybil and false positives.
In Round 12, we did not make any changes to this parameter, and maintained the aggressiveness level at 30 percent. Part of normalizing the tuning and processes allowed for more focus on the human evaluation part of the pipeline, feeding that data back into the algorithm, and establishing these parameters as the starting point for handing off ML pipeline operations to the Gitcoin DAO Dev Ops team.
Altogether the Sybil detection process, including Human Evaluations, ML Predictions and Heuristic Flags, flagged 8,100 contributor accounts as potential Sybil out of 28,987 total contributors (27.9%). This is a significant increase in Sybil instances in GR 12, representing anywhere from a 2–5x increase over GR11.
If we treat the high-confidence scores of the human evaluation subset as representative of the True Sybil Incidence, the Flagging Efficiency Estimate for GR 12 is estimating that the ASOP pipeline is flagging about 140% of users as potential Sybil accounts, compared with human evaluation and flagging alone. This could be interpreted in several ways:
1. The combination of human & Machine Learning algorithms are better at detecting Sybil accounts than just humans alone.
This would not be too surprising a result — the benefits of ‘centaur AI’ (i.e. human-AI teams) performing better than teams comprised solely of humans or algorithms can be seen in fields ranging from chess to medical imaging. It is possible that the ML algorithms are able to make more nuanced predictions based on large amounts of data than their human counterparts. Or…
2. Our flagging algorithm is tuned to be overly aggressive.
The aggressiveness parameter is always open for adjustment, but in this case we do not feel this is necessary. Due to the fact that we are dropping all human flags but the most confident in the estimation of True Sybil Incidence, 140% flagging efficiency is still within a feasible range. If we were to include all human flags instead, we would expect to see a lower flagging efficiency.
To compare the various flagging methods used in the Sybil detection pipeline, the below diagram is a relative distribution of the Sybil scores assigned per user evaluated, across different forms of evaluation processes in the ASOP. This compares the Y% of users predicted/evaluated to be X% likely to be Sybil accounts, for each of the ML Algorithm Prediction, the Human Evaluation, and the Heuristic Flags.
Reflections & the Road Ahead
We have come a long way since the first call for Sybil defense a year and a half ago. We are making huge strides in understanding what a Sybil attack fingerprint looks like, and our ability to take appropriate action to detect and deter adversarial behaviour at scale on Gitcoin Grants to protect the integrity of the system.
Thanks to the contributions of dozens of data scientists, stewards, contributors and the support of the Token Engineering Community, we continue to explore and improve the Anti-Sybil Operationalized Process and metrics for success.
Going forward, we will continue to develop insights from data analysis and support in preparing the Gitcoin DAO DevOps team to take on operations of the ML pipeline. To stay informed on developments and participate in the FDD workstream, join the conversation in the Anti-Fraud-Sybil channel in Discord, or keep up with the workstream on the forum: gov.gitcoin.co.
Apply to participate as a contributor to GitcoinDAO
Article by Jeff Emmett, Jessica Zartler, and Danilo Lessa Bernardineli with support from Charles M Rice.
