

At BlockScience, one of our research arcs entails building cyber-infrastructure for the organization and representation of knowledge and information. To do this we have to tackle a seemingly trivial question: What are the “things” which can be organized? What makes something organizable?
When we employ a digital system to organize — whether it pertains to software systems, corporate structures, or a social event — we are organizing something. We already have an intuition of what constitutes this “something” evidenced by our ability to pick out examples. Program modules, people's names, spreadsheets, spreadsheet cells, Slack channels, calendar events, and so on, are all identifiable as potential subjects or products of organizational processes. In this work, we are not interested in the meaning of a system's parts, nor what constitutes a “good” or “useful” part. We are instead addressing the foundational question of how it is that digital systems can have distinct parts to begin with which are amenable to being organized.
This inquiry is a vital first step toward establishing a robust set of first principles to guide our work building, and better understanding, new forms of organizational infrastructure for the socio-technical systems that are reshaping our world.
∗ ∗ ∗
To formulate the question better, let’s replace “thing” with the more appropriate term “object”. Philosopher Charles S. Peirce defines object succinctly as “a maximally general category, whose members are eligible for being referred to, quantified over and thought of”. Objects include everything from apples, the country of Egypt, to the number 7. This is in essence what we are looking to theorize in the digital realm — the category under which all digital things fall whose members can be enumerated, talked about, organized, and so on.
Files, programs, functions, calendar events, names, slack messages, etc. are all self-evidently digital objects, but having some intuition of their existence is not very useful by itself — to effectively reason about organization, we need a robust account of digital objects.
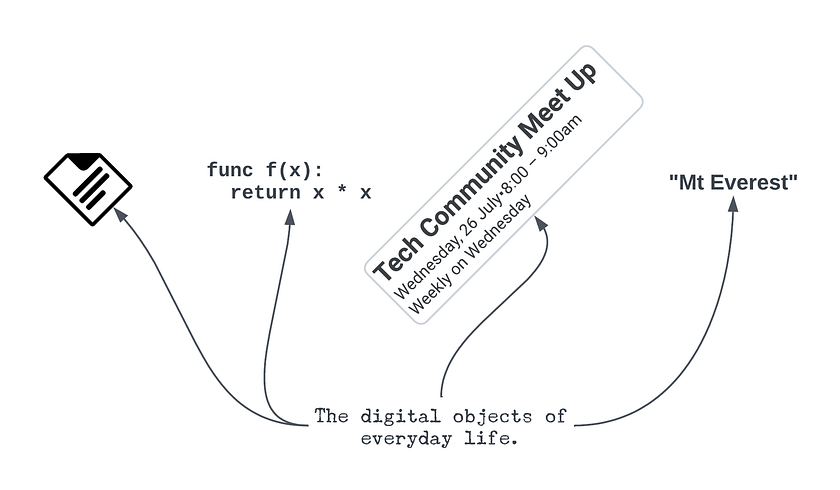
In this post we will introduce a new theory of “Objects as Reference” and aim to answer the following:
- What constitutes the nebulous category of digital objects?
- How can its members be identified?
- How can its members be analyzed?
Objects as Reference
We posit that all digital objects are references: A relation between a reference (a thing which refers) and a referent (a thing referred to).
These relations may be from a filepath to file data, a pointer to a location in memory, or even a name referring to an abstract concept. The referent (the thing referred to) needn’t be digital itself, it is the digital representation of reference which gives rise to objecthood and makes it possible to organize a digital system.
For example, you can organize a set of buildings into a spreadsheet that groups them by the country in which they are located; doing so, however, neither moves nor digitizes the buildings themselves. This is perhaps an obvious observation but this distinction between reference and referent is essential.
Let’s step back from examples for a moment and take a more abstract view.
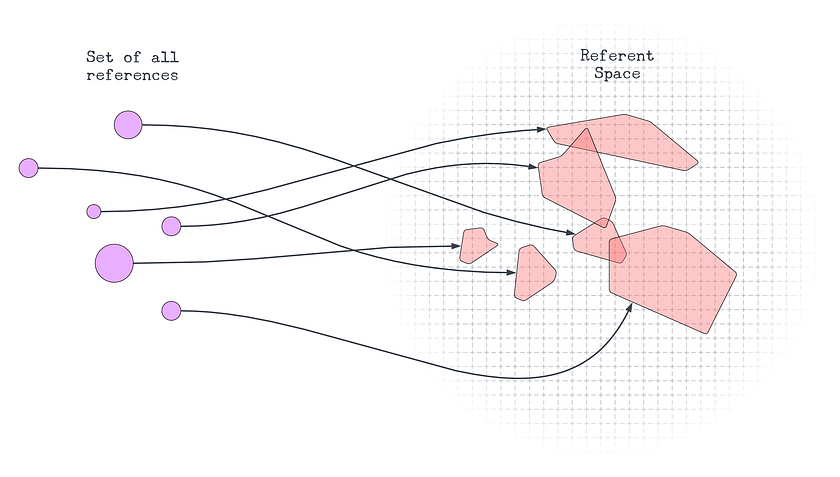
Consider the space of “everything” (𝑈) containing all the things in the physical universe (the planets, galaxies, and stars), as well as all the numbers, concepts, books, and computer programs. Within this space there are regions which we can, in principle, refer to¹.
We might call the region(s) of 𝑈 which can be referred to a referent space: everything which can be on the “receiving end” of a reference. We can intuitively imagine digital objects as a relation between a digitally-represented reference (an ID, a word, a database query) and some region of this referent space.
We can define or create more objects through referencing new parts of the referent space — dividing up or creating distinctions in an otherwise homogeneous territory. Note that objects are distinct but not necessarily discrete, as referents may overlap. By creating references we discretize the referent space into distinct objects.
This leads us to the central claim of this theory: That the category of digital objects is the category of any and all distinct things in a digital system.

This theory is a first step towards an axiomatic foundation for understanding organization in digital systems. It is a pragmatic theory too, because while there may be digital objects which fall outside of this definition, we cannot make use of any such objects without referring to them first.
[1] There are also things which we cannot refer to, such as stars beyond the observable universe, or mathematical structures which have not been invented yet.
Discriminators: Distinguishing Between Objects
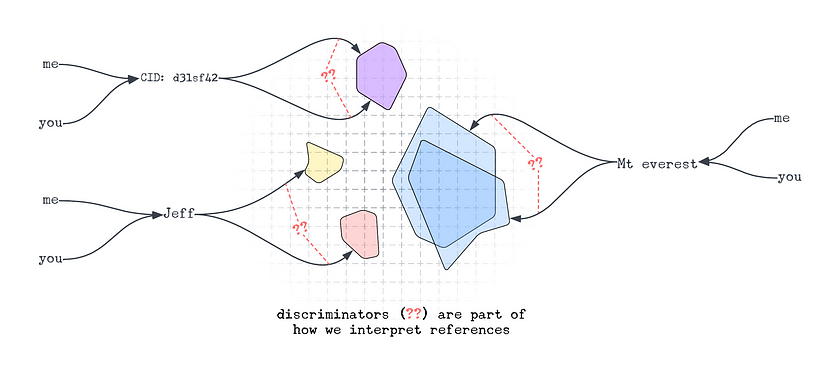
At the point of expression or interpretation, reference requires some “discriminator” which attempts to distinguish the referent from “not that referent”.
Every subject (i.e. person or agent) has (consciously or otherwise) a discriminator whenever they reference an object. These discriminators need not be consistent with each other — the way in which a word picks out a referent from “everything” might differ between you and I — but these discriminators can be coordinated and aligned; we can agree with some precision what the referents of a CID or database ID are.
The lack of singular and shared discriminators is far from a bad thing. Ambiguity is part of why natural language is so expressive. It lets us handle contradictions, consider context, and communicate efficiently. The challenge is not to remove ambiguity entirely but to organize and regulate it as we already do with natural language.
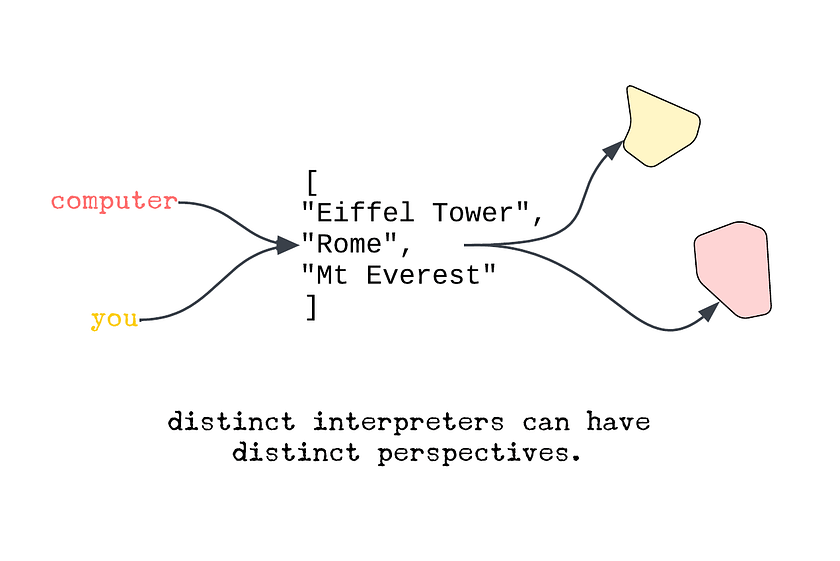
Different agents or interpreters may also have different perspectives. When a human programmer refers to a name in a list (e.g. with an index like name = locations[1]) it may be understood as a physical location on the planet Earth, a non-digital referent. However, to a computer, this may instead be a location in memory, a digital referent. Objects serving this role as coordination points is one way in which they form an essential link between social and technical systems.
An Analytical Toolkit
This semantic and pragmatic approach to digital objects provides us with some useful analytical tools. We can characterize reference relations (objects) with established tools in semantics, semiotics, and other disciplines. This lets us classify, compare, and study digital objects regardless of where they appear — allowing comparisons between functions and files, websites and database records.
Let’s look at three “dimensions of reference” to glimpse how an analysis of reference helps us understand objects themselves.
This approach to analysis is not really an analysis of objects per se but objecthood — the state or condition of being an object. For example, we can differentiate IPFS objects from database records, but not differentiate IPFS objects from each other. This does not replace existing approaches to analysis but can instead build bridges between discourses and provide shared language.
1. Temporal — Atemporal: Can the reference or referent change over time?
Example: Content-addressed objects (e.g. files in IPFS) are atemporal — neither their reference or referent change. Named variables in a python program are a mix — reference (the variable name) is fixed, but the referent can change over time. A file in a traditional filesystem is temporal as the referent (the data in the file) as well as the reference (the filepath) can change over time.
2. Independent — Dependent: An independent reference permits reference to an object directly (given some scope), whereas a dependent reference requires reference to another object.
Example: A PDF file, in the scope of a filesystem, is an independent object — you can refer to it via a filepath. The individual pages of that PDF are dependent because referring to a page requires reference to the PDF as a whole. Similarly, we can observe that the fields of a database record are referentially dependent on the record itself.
3. Endogenous — Exogenous: An endogenous reference is derived from, or dependent, on the referent. An exogenous reference is provided externally.
Example: A content-addressed object has an endogenous reference as it is derived, via a hash function, from the referent itself. A database record has an exogenous reference as it is provided by the database system through an incremental ID, Universally Unique Identifier (UUID), or some other means.
With these examples we can start to compare and articulate the differences between objects. For example we can see that a content-addressed system such as IPFS has objects which are atemporal and endogenous, while an append-only database may have objects which are atemporal and exogenous.
This approach also gives rise naturally to classes of objects which share characteristics. The study of filesystems, programming languages, or databases each deal with particular classes of objects, some more formally defined than others.
By providing a general account of objects we can build bridges between these discourses, share tools and insights, and design cyber-infrastructure which spans traditionally siloed domains.
The Organizational Role of Objects
In some ways, digital objects are to computing what atoms are to chemistry; they are the fundamental building blocks that underlie the structure and function of digital systems. Just as atoms combine to form molecules and give rise to the diversity of chemical interactions, digital objects combine to create the complexity of structured information and digital behaviors.
Unlike chemistry, however, digital objects are not uniform or regular — there is no general set of laws governing their composition or interaction. “Objects as Reference” advances our understanding of objecthood beyond our current intuition but it is not a substitute for good engineering. Just as civil engineering requires a foundation in materials science, we require an “immaterials science” for an immaterial world.
Digital objects serve as the units of organization that enable meaningful communication, representation, and interaction. They are in a sense the most basic shared ontology which mediates coordination between humans and digital systems. This shared interpretation between people, software, compilers, protocols, databases, and so on, produces an inter-subjectivity which reifies the organization of our digital systems.
Just as natural language arranges words or symbols to convey meaning, digital systems rely on the organization of digital objects to do the same. Objects serve as both the subjects which are predicated upon and the building blocks of those predicates. In essence, they determine “how we can talk” and “what we can talk about”.
Organization is built on forms of expression that encode the way in which objects are arranged or structured. In natural language we have words which can serve this role, as in the following example:
The cat is on the mat.
To an English speaker, this sentence encodes a relationship between two objects (a cat and a mat), with words acting as subjects, linking verbs, and prepositions which, when combined under some grammatical rules, express a relationship.
For organization to be useful it must be shared. The example above is only meaningful to the extent that you, the reader, is able to interpret English, and that I, the writer, am expressing it in a way that you understand.
By understanding objects as reference we can reason about the possible units of organization — the parts, entities, items, elements, and artifacts of digital systems — and how these objects are organized across system boundaries and contexts.
Conclusion
This work advances our understanding of organization beyond our current intuition. It gives us an approach to analysis and characterization, and helps us understand and design the “materials” of computing so that we can do better systems engineering.
We are applying this work to the development of new cyber-infrastructure for organizing. This infrastructure is orthogonal to the tech stacks of today — enabling variety and pluralism in the organization of data, models, compute, and the many classes of objects which form the complex systems of computing.
We are building protocols for shared knowledge, developing knowledge networks between organizations, and supporting the agency of users and communities to organize systems in ways appropriate for their own contexts.
This article was written by Orion Reed, with contributions and reviews provided by Ilan Ben-Meir, David Sisson, Michael Zargham, Jessica Zartler, and Dan Furfari.
About BlockScience
BlockScience® is a complex systems engineering, R&D, and analytics firm. By integrating ethnography, applied mathematics, and computational science, we analyze and design safe and resilient socio-technical systems. With deep expertise in Market Design, Distributed Systems, and AI, we provide engineering, design, and analytics services to a wide range of clients including for-profit, non-profit, academic, and government organizations.
