
By Michael Zargham & Ilan Ben-Meir
“Language is the liquid that we’re all dissolved in.
Great for solving problems, after it creates a problem.”
— Isaac Brock
By now, everybody has heard some version of the claim that the invention of LLMs has the potential to reshape our society on a structural level. Exactly what these sweeping changes will consist of, however, is often less clearly stated — and the specific mechanisms that will bring them about are usually even more obscure.
In this piece, we explore one way that LLMs might meaningfully remake our world: specifically, by providing infrastructure that makes it possible for smaller, specialized organizations to link up into heterogeneous assemblages, or “knowledge networks.” Within these networks, member organizations will be able to collaborate in ways that give them significant operational advantages over the larger and more monolithic organizations that dominate today’s landscape.
Historically, individuals form organizations because there are advantages to acting collectively when pursuing a common purpose, such as lower costs for actions and higher trust between members than would otherwise exist.¹ As an organization grows in scale, it is able to increase the efficiency of its operations by bringing a growing share of those operations “in-house” — that is, making them internal to the organization in question — but this increase comes at the cost of less efficiency in that organization’s interactions with other organizations.
This trade-off makes intuitive sense: As an organization handles more functions, its need for additional bureaucracy increases at a superlinear rate, while the need for that organization to coordinate with other organizations in order to have functions provided for it diminishes. A decrease in the regularity of inter-organizational coordination, however, causes the cost of each such interaction to rise, insofar as the organizations attempting to coordinate will have less in common than they did when they were more deeply interdependent.
The more pronounced an organization’s individual identity, the greater the difference is between that organization and others; in other words, the more an organization is “like itself,” the less it is like other organizations. In practice, small, highly specialized organizations tend to be a bit eccentric. The fact that today’s landscape is dominated by big monolithic organizations is a direct consequence of the historically high cost of coordination between organizations, relative to coordination within organizations.
It is far easier to enforce regularity within organizations than amongst them. Furthermore, it is often the case that the organizations best able to coordinate complex functions are those organizations that are large enough to contain that complexity within themselves.² But what if it was possible to bring the cost of coordination between multiple smaller and more specialized organizations down to a cost comparable to that of coordinating a single large organization? What would happen then? How might the structure of organizations and their relations change?
Multi-Agent Systems
We propose that if the cost of inter-organizational coordination can be brought low enough, then we would eventually reach a tipping point: The inefficiencies involved with the governance of large organizations will come to outweigh those associated with networking several smaller organizations together for the purposes of coordinated action toward a common goal.
At that point, the greater resilience of these “knowledge networks” will enable them to out-compete larger and more monolithic organizations — and legacy organizations will need to become flatter networks of specialized units in order to remain competitive. Because knowledge networks will be more fit to purpose than legacy organizations, such networks will rapidly become the primary drivers of innovation.
This conjecture might seem fantastical, but it is built on a solid foundation: the theory of multi-agent systems. According to Wikipedia,
A multi-agent system (MAS or “self-organized system”) is a computerized system composed of multiple interacting intelligent agents. Multi-agent systems can solve problems that are difficult or impossible for an individual agent or a monolithic system to solve.
Peer-to-peer networks (such as BitTorrent, Bitcoin, and Signal) are examples of peer-to-peer networks which can be understood as multi-agent systems. The three examples are made possible by protocols; their networks are made up of software clients which implement rules-based systems that adhere to their respective protocols. Humans must run these clients in order to access the affordances of these networks, such as enabling them to share files (BitTorrent), digital currency (Bitcoin), or messages (Signal).
Many of the limitations of such networks stem from the fact that the software clients which are peers within those networks function as “reflex agents,” meaning that they act by responding to their environment according to strict rules.
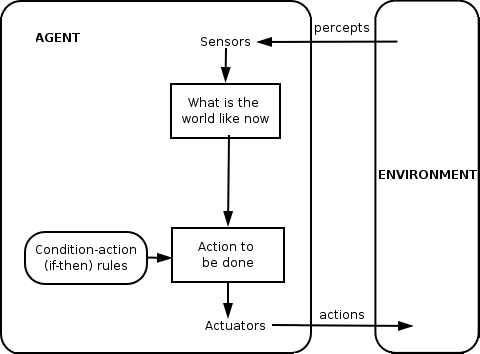
An agent senses information from its environment, computes the corresponding response according, then executes (or actuates) that response, thus altering its environment. These agents’ “environments” include human actors and other agents; the network’s “system level behavior” emerges from human-to-machine, machine-to-machine and machine-to-human interactions, but the machine agents themselves are limited to narrowly defined actions preordained by the client software. While the humans can learn, and change their behavior, the software agents are “reflex agents” since they only respond by reflex to inputs from their respective environments.
To the extent that multi-agent systems made up primarily of reflex agents exhibit a capacity to “learn,” this evolution does not occur endogenously; rather, that “learning” is primarily imported into the system by a network of human beings in meatspace who administer the agents’ software (albeit sometimes in highly automated ways, such as through CI/CD workflows).
Unlike reflex agents, human beings are “learning agents”; we can create persistent models of our environment (including the other agents acting within or upon it), update those models on the basis of new information, and adapt our goals accordingly.
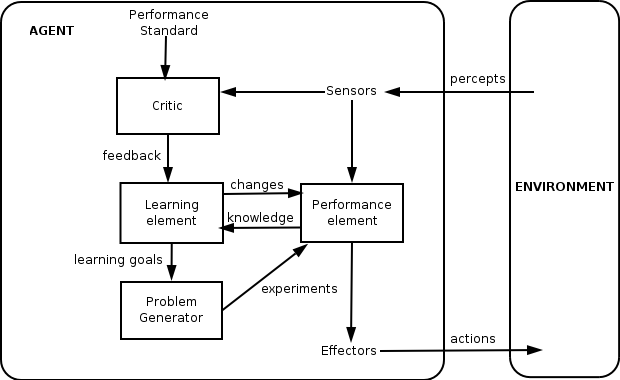
As seen above, this difference can be modeled by expanding the agent’s internality to include a second-order feedback loop. Instead of simply applying a rule to determine its action, the agent has a model of the world including (i) a “critic” or means of evaluating its sensory inputs, (ii) a “learning element” which allows it to update its internal model of the world, (iii) a “problem generator” which encodes preferable outcomes, and finally (iv) a “performance element” which uses sensor data, the internal model, and the goals to decide what instructions (or control signals) to pass to the effectors (a.k.a. actuators). Not only can a learning agent sense and act, it can maintain (and even update) a model of itself and of its relationship to its environment.
Networks of human beings are powerful in part because our agency maps onto this more complex model; our “learning element” consists, roughly speaking, of the internal models of the environment and other agents that we persistently maintain and consistently update.
Common internal models inevitably develop among any group of humans who reliably share a context (such as living together, working together, or participating in the same club) and communication channels — but as a group grows in size and complexity, its members begin to run up against limitations; it becomes impossible to carry all these models around in their heads, especially when coordinating shared resources is important to the group.
To lighten the cognitive load, groups often externalize (and align) their individual models in the form of group-level tools. As the group standardizes their model of the world suitable for group decision making (rather than individual decision making), that group can be thought of as an agent, itself.³ It can create and maintain shared knowledge, generally by using knowledge management tools such as spreadsheets, Github repositories, databases, and more.
Cyborganization & Cyberinfrastructure
All organizations are cyborganizations — that is, their operations are at least in part mediated by information technology. Insofar as an information technology provides affordances to (and imposes constraints on) an organization, we call that information technology cyberinfrastructure.
To the extent that different organizations have different purposes each will require different forms of cyberinfrastructure — including different sorts of shared knowledge management tools — in order to pursue its particular purpose. For example, an ethnographer embedded in and collecting data from an online community may use a Discord bot and database of logged messages, as well as recordings of interviews, and research notes.⁴ The manner in which community members access the ethnographer’s research may be nontrivial for ethics and privacy reasons.
An open source software development community may prefer more permissionless cyberinfrastructure, such as a public Github repository for managing software code and documentation, as well as scoping work and tracking contributions. A community developing a new research field needs needs to maintain a balance between inclusivity and accessibility by gating their spaces to people who have invested the time to work through public education materials. Such communities commonly use wikis as a core cyberinfrastructure, because wikis offer public content while restricting authorship to experts.
All three examples involve local choices of cyberinfrastructures, which impacts both who can access relevant knowledge artifacts and who is able to make sense of their contents. Because technical tools are chosen based on their fitness to a particular organization’s purpose, organizations with distinct purposes will require different forms of cyberinfrastructure. Fitting cyberinfrastructure more tightly to an organization’s purpose, however, comes at the cost of reducing its similarity to other organizations with which it might coordinate.
One can think of the cyberinfrastructure an organization uses as akin to a dialect which that organization speaks. We don’t want every organization to be forced to speak using the same dialect, but we do want to make it easier for two organizations to find a sufficiently common language that each is able to genuinely understand the other, and to respond in ways that the other will understand.
Driving down the cost of inter-organizational coordination will therefore require developing a new architecture for cyberinfrastructure that is sufficiently general to enable organizations with distinct purposes and significantly different forms of local cyberinfrastructure to nonetheless interoperate at a technical level well enough to form deeper links with other organizations.
Cyborganization as Learning Agent
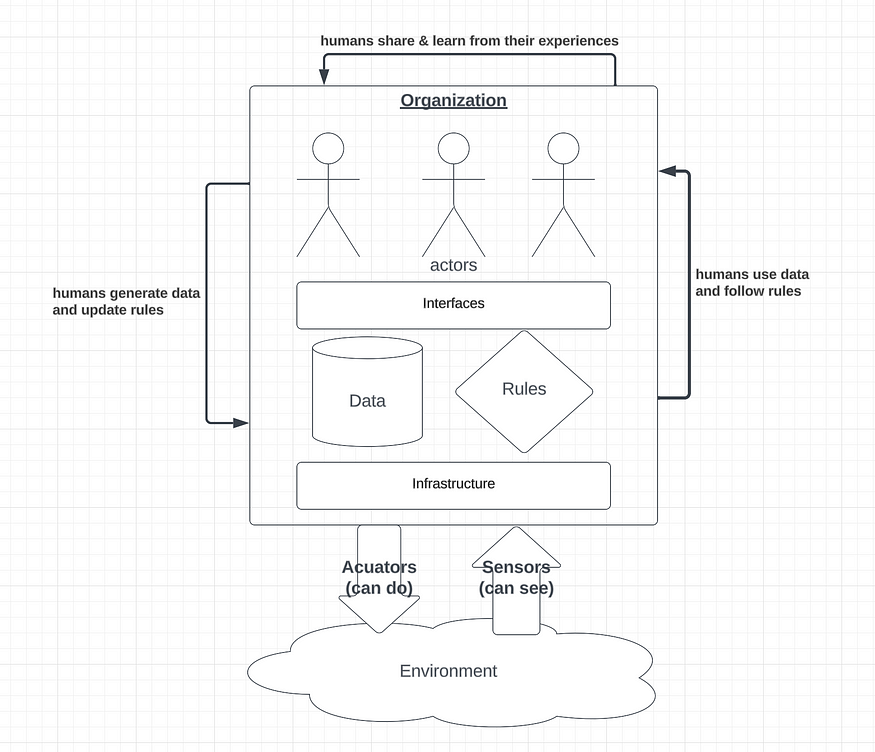
An organization is a cyborganization insofar as it consists of infrastructure, which determines how an organization internalizes (that is, structures and stores) the data and rules that are relevant to its operations; the data and rules hosted on (and thus are structured by) that infrastructure; humans, whose activities can generate data or consume it, and who either follow rules or update them; and the interfaces through which these interactions between humans, data, and rules take place. A (cyb)organization’s cyberinfrastructure is the assemblage of data, rules, interfaces and infrastructure which mediates its human activities.
Human-to-human activities consist of sharing experiences with, and learning from the experiences of, other humans. Human-to-machine interactions take place when these humans generate data or update rules; conversely, one can view humans’ consuming data or following machine administrated rules as machine-to-human interactions. Machine-to-machine interactions include (but are not limited to) circumstances where data is used to update rules pursuant to a goal, or where rules are applied in order to update existing rules. It is common for an organization to use many pieces of software to coordinate, so machine-to-machine activities often take the form of integrations and automations like those made available by Zapier.
All of the above, taken together, comprise the organization as a system, which interfaces with its environment through its sensors (which enable the organization to gather information about the world), and its actuators (which enable the organization to act in ways that cause the world to change). The interactions between an organization-as-system and its environment tend to be heavily intermediated by technology — which means that the technologies in question must be relatively interoperable, in order for organizations to be able to interface efficiently with one another.
Returning to our earlier discussion of “reflex agents” and “learning agents,” recall that these two categories of actors are differentiated by the latter’s capacity to acquire and apply knowledge. Consider the fact that the decrease in coordination costs that results from an organization internalizing a function which had previously been outsourced to another organization is primarily because doing so allows the organization to make decisions on the basis of knowledge of its own internal state, rather than on the less-reliable foundation of inferences that it must draw about the state of the external world.
There is a crucial difference between a organization’s “knowledge” and the “rules” that it has developed for acting on the basis of that knowledge: If two organizations with distinct purposes compile their knowledge into a combined (and shared) set, each becomes more able to pursue its own goals (even as it collaborates with the other) — but if two organizations with distinct purposes compile their rules into a combined (and shared) set, each becomes less able to pursue its own goals whenever it attempts to collaborate with the other.
The costs associated with inter-organizational coordination can be drastically reduced simply by increasing the accessibility and interoperability between organizations of what has historically been primarily internal organizational knowledge. In order for such knowledge-sharing to be possible, however, we must first develop a new form of Knowledge Organization Infrastructure (KOI) — so we have a research initiative at BlockScience dedicated to exactly that.
Building Our Knowledge Management System
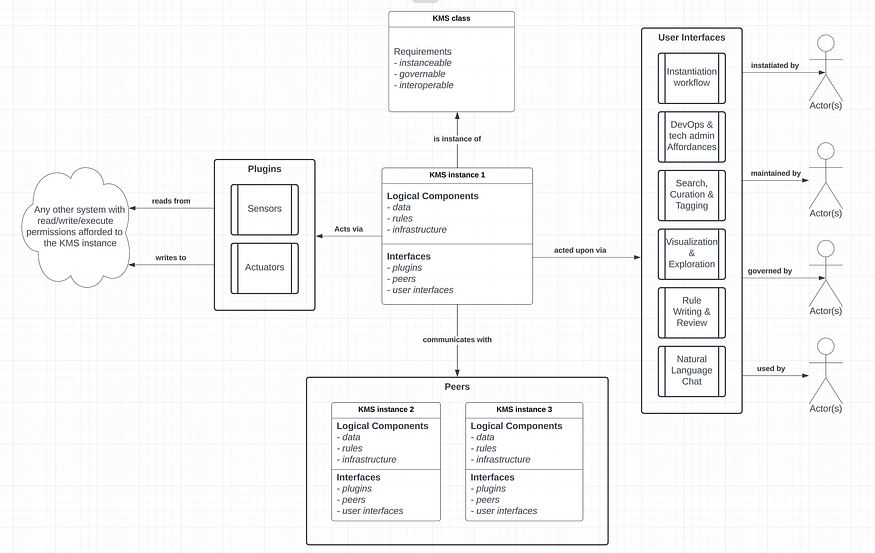
The flagship project of our Knowledge Organization Infrastructure (KOI) initiative is called the Knowledge Management System (KMS).
To meet our needs, we assembled BlockScience’s “knowledge graph” using a concept we have developed called Reference Identifiers (RIDs), rather than relying on a pre-existing product — a necessity, given our emphasis on distinguishing observations about the world (“the map”) from the world itself (“the territory”).
RIDs define digital objects as references which point to referents. References also have a method, or way of referencing, their referent(s). A single referent may be referenced by any number of digital objects, in a wide variety of ways. RIDs are an important innovation because they provide the basis for triangulating complex referents through many perspectives, which also enables communication across contexts where different references are used to describe the same referent.
We applied the concept of RIDs when we built software to collect and curate a library of digital objects. We organized our library into a graph database in order to explore its items and the relationships between them. By using RIDs, we eliminate the need to replicate knowledge objects distributed across various platforms in order to make use of the knowledge that these objects refer to. When necessary, we can “dereference” these RIDs by applying their method of retrieval in order to recover their contents. Our graph database is like a card catalogue, a node in the graph is like a card for specific book, and dereferencing is akin to taking a book out of the library.

Our goal for this project is to balance the trade-offs between the amount of human manual labor required for shared knowledge management, the quality of the data, and the practical affordances offered to the human users. In other words, this design leverages the principles of Calm Technology, as it is oriented toward producing a more harmonious relationship between humans and the tools we use. This goal is approached through careful attention to the various users, use contexts, processes, interfaces and information flows that occur inside (or involve) the organization as a complex system. This project also includes legal and operational considerations related to privacy, data security, and context-specific access rights for organizational data.⁵
Why We Need RIDs
The concept of a reference identifier (RID) is critical to the kinds of Knowledge Organization Infrastructure we have been working to develop, because the ability to differentiate between reference and referent makes it possible for organizations to learn and share knowledge about objects without mistaking the map for the territory (that is, the reference for the referent).
Existing database systems allow organizations to communicate facts; RIDs allow communication about beliefs, without simply reducing beliefs to probability distributions over (would-be) facts. Interoperable technical systems made of reflex agents facilitate communication — but in order to turn communication into effective coordination, we need learning agents — agents that can develop, maintain, and update beliefs about a referent without mistaking their beliefs for facts.
An organization often needs to update its internal representation of an external actor or organization, without misidentifying this internal update as a change to the external actor or organization itself — a process which RIDs make easy. Furthermore, differentiating reference from referent makes it possible for organizations to have internality on the technical level — which, in turn, makes it possible for organizations to communicate with other organizations about their internalities (that is, their organization’s knowledge), without having to also grant outsiders access to its inner workings.
A stable concept of a reference as something distinct from (but referring to) an underlying referent is thus the mechanism that enables organizations to interoperate while retaining (and securing) their respective boundaries.
Reference Identifiers and Learning Agents
At this point, BlockScience has developed a working prototype of a database built around RIDs — which we are in the process of refining into a protocol. Where having our own knowledge database leveraging RIDs helps us communicate within BlockScience, developing the RID concept into a protocol will make it possible for BlockScience to communicate (and thus collaborate) more deeply with other organizations also operating cyberinfrastructure compatible with the RID protocol.
Our RID design subsumes, rather than replaces, existing ID systems. If one understands Content-Addressed IDs or DIDs as particular implementations of the concept of Reference IDs, what we are trying to do is create a generalization of existing identifiers — such that it is possible, among other things, to have an array of identifiers that all point to the same referent.
This capability is vital because different organizations may well have different ways of referring to (or, if you prefer, “different perspectives on”) the same referent, making it essential to be able to recognize when organizations are, in fact, “talking (or thinking) about the same thing, but in different ways.” If this recognition can be automated, inter-organizational coordination will become significantly easier on the technical level — and on all of the higher levels built atop that cyberinfrastructure.
What LLMs Have to Offer
The last major piece of this puzzle, therefore, consists of providing an interface that can translate the internal “private idioms” of distinct organizations into a single “common language” understood by all participants in a given “conversation,” and this is where LLMs shine. An LLM, after all, fundamentally functions by analyzing the deep relationships between meanings and the various modes in which those meanings can be expressed or enunciated. If it were possible to “teach” an LLM everything that your organization “knows,” then the LLM could render that knowledge interoperable with the knowledge of other organizations.
This insight motivated us to redesign our internal Knowledge Management System. Rather than interfacing with KMS by directly querying the graph database, our company has produced a localized LLM using the GPT-3.5 foundational model. Practically, this was accomplished using a vector datastore which makes those digital objects accessible for Retrieval-Augmented Generation (RAG).
If we briefly anthropomorphize the LLM, then we might say the data available for RAG is the model’s “long term memory,” in contrast to the “short term memory” which is the context provided during a prompt engineering session. Through RAG and prompt engineering, we supply the LLM with the organization’s local knowledge with which to do its work: charting relationships between distant digital objects, and navigating the gnarled knot that is the space of related references.
Rather than trying to fine-tune a specialized model (which would be expensive and labor intensive), we simply encode our organization’s knowledge into a system that is harmonized with its users. The users can communicate knowledge to the system through the creation and curation of data (often generated automatically from their work activities), and the system can communicate to the users through knowledge graph visualizations and LLM-based natural-language conversations. As can be seen in the image below, the results of this experiment have already been quite remarkable.

It is crucial to remember that the LLM is not an end unto itself; its primary value is as an interface to the internality of an organization (which consists of its collected organizational knowledge, and the cyberinfrastructure in which that knowledge is embedded). Insofar as “natural language” is humanity’s natural language, the LLM as interface makes it possible for humans to access and interact with an organization’s knowledge in a more natural way. One can think of using LLMs in this way as a “Calm Technology” for knowledge management.⁶
The use of LLMs as an interface to organizational knowledge raises the same fundamental questions of governance that arise during the design of any interface: Who should have access to what information, and under what circumstances? What should be included in the vector database used for RAG, and what should not? How should such decisions be made? The set of questions related to access control is a particularly fertile area for further research and development.
Conclusion & Future Work
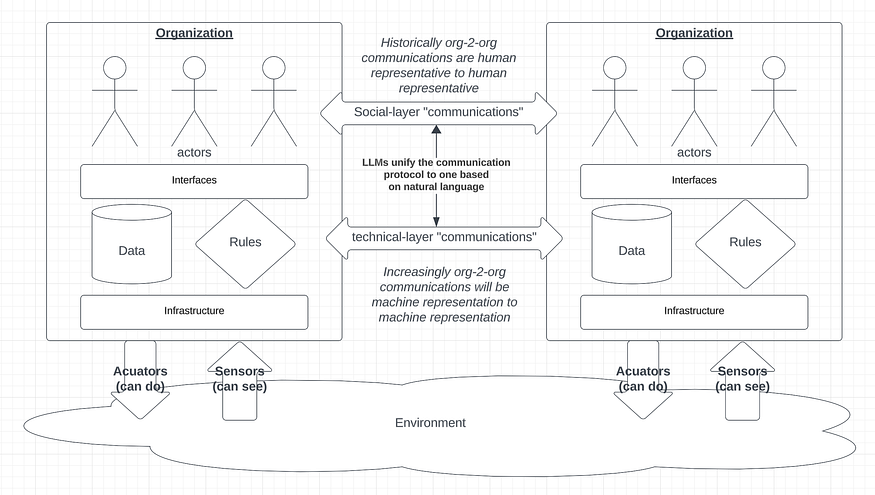
While BlockScience’s KOI initiative has thus far focused primarily on refining the ways that we, as an organization, interface with our own organization’s knowledge, the ultimate goal has always been to develop cyberinfrastructure that can support conversations between organizations.
Such conversations historically have taken place between human representatives of the organizations involved, and therefore often suffer from missing context or principal agent problems. These problems do not magically disappear with the advent of RIDs, but the introduction of richer human-to-machine and machine-to-machine relationships unlocks a larger design space for organization-to-organization relationships and interactions.
The theory of multi-agent systems and learning agents provides the basis for imaging a future where small specialized firms develop deep enough relationships to form knowledge networks that can outcompete large institutions, especially with regards to innovation.
The concept of Reference IDs makes it possible for different organizations to operate cyberinfrastructure that is fit to their distinct purposes — to have distinct internalities — while still being able to develop deep and more meaningful relationships with other internality-possessing organizations.
Our KOI research focuses on developing cyberinfrastructures, including LLMs, which provide the technical capacity to model and reason about other organizations and their respective internal models of the world — offering a technical grounding for theory of mind at the organizational level.
Finally, the innovation of using LLMs as the interfaces to these knowledge bases provides the common language through which these internalities can connect, converse, and coordinate. Ideally, organizations engaging in these networks will come to richer (and more actionable) understandings of their common world without enforcing a universal world-model that all must share. The most fundamental “knowledge network” is, after all, nothing more than a conversation between open-minded peers.
Insofar as knowledge networks can only emerge from collaborative coordination between peers, it is impossible for any organization to build the high-tech knowledge networks that we envision on its own. The grand project of building such networks must, itself, be a collaborative enterprise.
Our work on digital objects has thus emerged from an analog knowledge network that has served as a prototype for the more technologically-advanced knowledge networks that we envision. This self-referentiality is instructive: There is no way to manifest a knowledge network other than to collaborate with trusted peer organizations. The first step of automating any process is to do the task manually; automating something poorly is worse than not automating it at all. If handled with care, our cyberinfrastructure can deepen our collaborations, and make new ones possible.
In accordance with this strategy, BlockScience turns to several of its peers: The Metagovernance Project, Marvelous Labs, and The Active Inference Institute. To answer the urgent questions concerning access control and governance of digital spaces that our work has raised, we need access to the organizational knowledge that The Metagovernance Project has developed. To think through how information design, user experience and Calm Technology apply to these knowledge management systems, we draw on the expertise of Marvelous Labs. To examine the learning capabilities of knowledge networks through formal mathematics, computational science and biomimetic systems, we will learn from the Active Inference Institute.
The protocols that we are developing are designed to make interdisciplinary collaborations of this complexity possible — so we will continue to test the ideas discussed here, through our own attempts to put them into practice. The knowledge network need not stop there — our focus is on developing systems which are instanceable and governable by the orgs that deploy them; knowledge networks can form and grow organically.
Special thanks to David Sisson, Orion Reed, and Luke Miller for developing the software systems described above, as well as to Amber Case, Eric Alston, Kelsie Nabben and Daniel Friedman for discussions contributing to this piece.
Endnotes:
[1] For a more detailed examination of how organizations come into being, the work of Eric Alston is invaluable — particularly the papers “Governance as Conflict: Constitution of Shared Values Defining Future Margins of Disagreement” (2022), “An Organizational Coase Theorem: Constitutional Constraints as Increasing in Exit Costs” (2022), and “Leadership Within Organizations” (2021, co-authored with Alston, Lee J. and Mueller, Bernado).
[2] Ashby’s Law of Requisite Variety tells us that an organization (or organism) must have at least as much complexity as the environment it operates within. Cf. Ashby W.R. (1958) Requisite variety and its implications for the control of complex systems, Cybernetica 1:2, p. 83–99. Furthermore, Ashby’s articulation of how the organization of a whole relates to its parts can be found in Ashby, W. R. (1962). “Principles of the self-organizing system,” in Principles of Self-Organization.
[3] In Zargham et al (2023) Disambiguating Autonomy: Ceding Control in Favor of Coordination, we explore the ways in which organizations balance individual level and group level decision making processes pursuant to group level goals.
[4] Cf. Rennie et al (2022), Towards a participatory digital ethnography of blockchain governance. Qualitative Inquiry. This piece provides an example of a methodology and associated information technology enabling an ethnographer a community to more effective coordinate the collection of ethnographic data about that community.
[5] Cf. K. Nabben (2023) Constituting an AI: Lessons about Accountability from a GPT Experiment. [Forthcoming].
[6] Cf. Case, Amber (2015). Calm Technology. O’Reilly Media. Case’s book develops the concept of Calm Technology, with an emphasis on designing the way in which humans and technologies interact in order to ensure that the right information gets to the right place at the right time, without overloading or distracting the user. Calm Technology allows attention to remain on the task, rather than the tool.
About BlockScience
BlockScience® is a complex systems engineering, R&D, and analytics firm. By integrating ethnography, applied mathematics, and computational science, we analyze and design safe and resilient socio-technical systems. With deep expertise in Market Design, Distributed Systems, and AI, we provide engineering, design, and analytics services to a wide range of clients including for-profit, non-profit, academic, and government organizations.
