
Mitigating Risk in Algorithmic Trading for Semi-Fungible Carbon Assets
BlockScience is actively researching how to build effective algorithmic traders for semi-fungible asset markets using Automated Regression Market Makers (ARMMs). This pioneering, open-source price discovery mechanism could help transform the $851 billion carbon markets and $2 billion Voluntary Carbon Markets by accelerating carbon credit transaction clearing.
In our previous article, we introduced the concept of these automated market makers for price discovery for assets with multiple attributes and a first use case application in carbon credit markets.
Here, we will cover the risks and benefits of ARMMs for price discovery and trading using traditionally managed order-book markets as our baseline. We will explore a related area of algorithmic trading — namely financial quantitative trading strategies, or quant trading for short — and use lessons learned by developers of quant traders to suggest how to go about developing and deploying ARMMs such that benefits are maximized and risks are minimized.

Meeting the Needs of a Global Offset Shortage
A looming shortfall in credible and tradable carbon offsets threatens to derail carbon trading, and carbon offset prices are predicted to increase fifty-fold by 2050 due to a growing undersupply of offsets that remove, store or sequester carbon to achieve net-zero targets. BlockScience is developing a new open-source signal processing and price discovery mechanism dubbed Automated Regression Market Makers (ARMMs), which have the potential to enhance liquidity and increase transaction clearing in carbon markets. The team is collaborating with research and development partners Hedera, Object Computing, Inc., and Tolam Earth to develop an exchange protocol that offers the ability to develop highly-liquid, publicly-auditable, automated Environmental, Social and Governance (ESG) marketplaces based on open data and price discovery.
Fungibility as a High-Dimensional Vector Space
In emerging Web3 markets where assets are represented by digital tokens, there has, until now, only been a recognition of fungible and non-fungible tokens (NFTs). In our paper, “A Practical Theory of Fungibility”, we introduced a mathematical formalization for degrees of fungibility, or semi-fungibility — where goods can be differentiated by their “underlying attributes and the perceived value and/or usefulness of those attributes to a value assessor.” We also introduced the theoretical concept of an Automated Regression Market (ARM), in which the prices of the goods for sale are based on the attributes of said goods and which has the ability for automated transactions based on those attributes to occur.
What is an ARMM?
An Automated Regression Market Maker (ARMM) is a market-level price discovery mechanism. It is an automated agent deployed within an ARM and is capable of measuring the state of the market, making direct trades, and leveraging the mathematical similarities between machine learning (ML) models and Automated Market Makers (AMMs). It differs from price discovery mechanisms such as AMMs in that they work when one fungible asset is being traded for another. ARMMs can be used when the assets being traded on a market share some similarities, but they are not all the same.
An ARMM trades assets that are described by extremely rich sets of attributes. In mathematical terms, such an asset is a point in a very high dimensional space. Individual trades of these assets are made in contexts that weigh regions in the attribute space differently.
At its core, an ARMM borrows techniques from ML modeling to evaluate potential trades. It uses dimension reduction techniques to discover clusters of related attributes on which it estimates the value of those attributes using an energy function tuned by prior trades.
Seeing Carbon Credit Markets in High Definition
ARMMs enable automated trading of semi-fungible assets, such as carbon credits or carbon offsets/removals containing varying attributes. This enables efficient price discovery for highly complex arrangements of attributes, such as (for carbon or energy credits) the type of energy generation, geographic location, etc. For example, if a business wants to purchase a solar energy credit produced in the Pacific Northwest in the United States, the asset the buyer wants would not be substitutable for a credit produced in Asia.
People participating in these markets want to understand which attributes are highly sought after, as well as which are more commonplace, in order to exercise their purchasing power whilst meeting legal and jurisdictional requirements. Additionally, this capability could provide value by making carbon and energy credits discoverable on a public ledger with a verified link to their auditable source.
Facilitating price discovery for semi-fungible assets
Within an ARMM, the semi-fungible goods — “bundles” of various attributes — take on different weights depending on market conditions and the context in which they were produced. As the demand for attributes changes, their relative valuation within an asset should also change. An ARMM updates its asset valuation according to the relative demand for attributes, resulting in a dynamic price discovery process that continues to facilitate exchange when external demand changes over time. This supplies the market with better information for matchmaking across supply and demand parameters.
Accelerating Impact with ARMMs
ARMMs are designed to enhance liquidity in the climate markets and maintain full auditability of all attributes, roles, and actors throughout their lifecycle. They could provide automation that would allow massive scaling and expansion of carbon markets and trades, accelerating market development and providing the potential for futures markets. Cost could also be reduced for individuals, smaller carbon offset producers, or cooperatives who could more easily aggregate diffuse power generation networks to provide collateral or tokenized assets in exchange for access to financing.
With more efficient and expanding markets and higher visibility into carbon offset production and attributes, there would be a greater incentive to improve and invest in infrastructure that met higher or “more valuable standards”, or standards demanded by markets. More visibility in localization could also provide the possibility for locally produced value to be maintained within those boundaries, rather than be extracted to larger markets (i.e. assets produced by diverse, local cooperatives vs. monopolies or multinational corporations).
Avoiding inappropriate asset commoditization
In the absence of ARMM-like mechanisms, commoditization can be an efficient price discovery mechanism for a market for certain asset classes. Commodity markets define a priori a required attribute set an asset must have to be traded on the market. To a commodity market, all tradable assets are equivalent, i.e., fungible. This is both efficient and effective provided the chosen attributes capture the lion’s share of the asset value. When this is not the case, commoditization may leave value on the table in the form of attributes that are not part of the commodity specification. We will call such a market attribute-based.
Media advertising is an example of value capture by successful transition from commodity trading to trading based on broader consideration of attributes. Mass marketing, filling pre-scheduled spots in mass media outlets such as newspapers, and broadcast radio and television, was enabled through ratings services such as Nielsen who estimated viewership in coarse, a priori groupings. Mass marketing was efficient, but it led to advertiser sentiments popularized by statements such as John Wanamaker’s, “Half the money I spend on advertising is wasted; the trouble is I don’t know which half.”
Segue to the present day ubiquity of targeted advertising platforms power attribute-based markets that decide in real time which ads to display based on rich attribute sets about the viewer, the content surrounding the ad, and the ad copy available for display.
Targeted advertising platforms power markets that capture more value for market participants, namely advertisers and content providers. However, today’s ad markets are notorious for ignoring the values of viewers, who are market goods — not participants. Viewer values such as data privacy, consent, and message accuracy are therefore market externalities.
An ARMM takes into account all the attributes of an asset in its estimation of the asset’s market value. In this way, an ARMM can discover value in attributes ignored in commodity markets. This also gives an ARMM the powerful ability to internalize what would otherwise be considered externalities (a common problem in our current economy, particularly with regard to environmental destruction), an aspect with exciting potential in various contexts and applications.
Mitigating Market Contagion
Because an ARMM prices all attributes into its estimated market value, any shocks that occur remain identified with an asset rather than generalized to an entire commodity space. Supply shocks such as geopolitical or firm-specific events, and heterogeneity in demand such as cultural norms or average preferences, are reflected in the attribute space rather than the price of a single commodity, limiting the spread of the shock to other assets. By contrast, a commodity market (by definition) forces shock valuation into the price of a commodity, causing an immediate spillover of regional disruptions to the market as a whole.
Exploring & Mitigating Potential Risks
Our goal is to strike a balance between the correlation-based compression capabilities of machine learning (ML) with the discovery capabilities of markets. We acknowledge also that with any technology or innovation there are many ripple effects that are as yet unexplored — and with any new territory comes the potential for unintended consequences and systemic effects from new market mechanisms. That is why we will be performing modeling and simulation work to optimize complex system design using a framework we built and open-sourced called cadCAD. We are working to develop a reference implementation to simulate market activity and test the signal processing capability of ARMM’s algorithms using data collected from carbon credit markets.
In our explorations so far, we have identified the following areas of potential risk and will be integrating these learnings into iterative design and mitigation strategies.
Analyzing known risks & acknowledging unknown risks
Dimension reduction and clustering carried out by an ARMM can be thought of as defining its awareness and attention, respectively. In this analogy to cognitive psychology, dimension reduction by definition introduces bias which, at an extreme, will produce “blind spots”. Problems arising from this type of bias can be categorized as known unknowns. The model has information that it has chosen to ignore.
Algorithmic awareness and attention is one thing. Algorithmic wisdom is quite another. (David Sisson)
There are also unknown unknowns, i.e., attributes for which an ARMM has no sensor. An algorithmic trader competes with order book markets run by people. If the people have access to information that the algorithm does not, then the algorithm is at a disadvantage. Real estate iBuyer programs are algorithmic trading systems for buying houses with the intention to rapidly resell, or “flip”, them. iBuyer programs are effectively ARMMs.
Zillow famously developed an iBuyer algorithm, Offers, that was shut down in 2021 at a loss. For an iBuyer program to succeed, it must accurately predict the eventual selling price of a property several months in the future. The offer to buy is based on the anticipated selling price. The delay is due to the time required to renovate the property for resale. Housing values are heavily influenced by hard-to-digitize, subjective feelings. A human actor is able to get a read on these feelings by asking questions. iBuyers are largely blind to this information unless of course they are fed inputs of these kinds of survey results.
Before Zillow’s experience with Offers sours the concept of ARMMs, it’s important to call out that any trader, algorithmic or human, is at risk of bad timing. Zillow stopped Offers in November of 2021, at the height of unprecedented volatility in the US housing market during the COVID epidemic. This volatility was a primary reason cited by Zillow for the decision to stop the Offers program. To compound the problem, Zillow seemed to be making a play for market share right when volatility became a problem. They increased Offer’s buying rate tenfold prior to shutting it down.
In addition to limitations around sensors and extenuating market developments, another core consideration learned from the Zillow example is that maintaining trading volume while maintaining a dynamic balance of assets owned and available cash is a key performance indicator of an ARMM. An ARMM must maintain its liquidity. Zillow was left owning thousands of properties. According to Bloomberg reporting, about 7,000 were sold in bulk to institutional investors. Essentially, they bought at retail and sold at wholesale. This is the antithesis of liquidity. It would be interesting to know how this weighed in Zillow’s decision to stop Offers.
Going back to the anthropomorphic metaphor, algorithmic awareness and attention is one thing. Algorithmic wisdom is quite another. Knowing that an ARMM will face unknowns, a human operator should always be in the loop. The operational question that comes out of the case study of Zillow Offers is not “why did the algorithm lose so much money?” Rather, it is “why did Zillow not stop the program sooner?”
Risk/Benefit Profiles of ARMMs and Quant Strategies
Given the benefits and risks of ARMMs discussed above, how should an ARMM be developed and deployed with an eye to maximizing its benefits while minimizing its risks?
Quant trading is an active area for the development of algorithmic trading software. Like ARMMs, quant strategies are automated trading systems that make decisions that have real-world outcomes. Both ascribe value to assets. Their decisions are based on this ascribed value. The outcomes of their decisions affect a Profit and Loss statement (P&L) in Traditional Finance (TradFi) terms or treasuries in Decentralized Finance (DeFi) terms. They are different in that ARMMs are classified as market makers that improve market efficiency and liquidity, while quant traders tend to be market takers that seek to gain an advantage in a market by optimizing for profit.
However, this difference does not change the comparability of their risk profiles. The goal in both cases is to use historical market data to develop and train a model that will be used to predict future states of the market. In this light, we can apply lessons learned in quant strategy risk mitigation to ARMMs.
Best practice for developing quant strategies centers on four phases:
- Exploratory data analysis (EDA)
- Backtesting
- Paper trading
- Small budget trading
Exploratory data analysis
“Data are not taken for museum purposes; they are taken as a basis for doing something. If nothing is to be done with the data, then there is no use in collecting any. The ultimate purpose of taking data is to provide a basis for action or a recommendation for action. The step intermediate between the collection of data and the action is prediction.”
-W. Edwards Deming, On a Classification of the Problems of Statistical Inference, June 1942, Journal of the American Statistical Association
To Deming’s point, any data analysis is done in some context for some end. What is this development for? What are the desired outcomes? For a quant strategy, a goal may be trading to maximize profits, e.g., taking advantage of the spread between buy and sell orders. For an ARMM, a goal may be trading to maximize efficiency, e.g., a market’s ability to clear orders.
The key to EDA is having historical market data from which an understanding of a market can be drawn. Can a market’s participants be divided into sectors? What are the internal and external factors that affect a market? Does a market exhibit behavioral patterns such as stationarity and volatility that can be classified stereotypically as system states? How do market factors differentially affect sectors across different states?
An implicit assumption in EDA is that the future market will look something like the historical one. This assumption leads to the need for as much data as possible. A sector, factor, or state that is not represented in the data will not be discovered by EDA. While more data is always preferable to less data, requiring that everything be known a priori is an impossible burden. New sectors, factors, and states may appear in the future. Available data may not represent all set factors and states that have occurred in the past. Unknowns are something that a developer of any decision-making strategy must accept. Unknowns represent risk.
Rather than being sure ahead of time that a system will perform well, a system must be monitored in real-time to assess how well it is performing. Similarly, the market in which a system operates must also be monitored in real-time. Signals that indicate how well a system is performing and signals that indicate current market conditions are identified by EDA.
The purpose of EDA, then, is fourfold:
- Understand what is expected of the system being developed
- Understand the market for which the system is being developed
- Understand the signals that indicate system performance and market conditions
- Understand the boundaries of what is understood about what is being developed
Backtesting
Backtesting uses the understanding developed by EDA to determine how prediction systems perform against historical market data, and to build a risk/benefit profile of the system. It examines a system’s attribution of value to factors, sectors, and trades. Value generated by a small number of sectors or factors indicates that the system does not generalize well across the market. Value generated by one or two trades may suggest that the system isn’t predicting the market, but rather that it just got lucky. Does the system effectively attribute value in all market states, or only specific ones?
The control plane of a prediction system is developed by backtesting. Input parameters that regulate a system’s predictions can be identified and tried against different sets of historical data. The system’s sensitivity to parameter changes can be determined. What parameter settings enable the system to be better tuned in different states? Just as important, the sensitivity of a parameter setting to changes in data can be determined. What parameter settings cause the system to be over-tuned to a given state?
The feedback loop between system decisions and performance indicators is developed by backtesting. System decisions can be what trades to make, or what parameter setting to use. Are there leading indicators that suggest what decisions to make? Are there trailing indicators that show decision outcomes?
The understanding gained about a system and its control plane will help to determine system boundaries. That is, under what conditions does the system provide benefit, and under what conditions is it at risk. Risk mitigation strategies, including appropriate ‘circuit breakers’, should be developed accordingly.
Paper trading
Paper trading operates the system in real-time using live data, but trades are not actually executed. Outcomes of the system’s trades are tracked, but there is no effect on P&L or treasury. Paper trading demonstrates that the system’s mechanics are properly implemented to provide necessary performance for operation under real-time constraints. Paper trading also demonstrates how the system responds to novel market data from current market conditions.
While paper trading provides a dynamic view of system operation, because trades are not executed, paper trading is blind to the effects that these trades would have on the market. In particular, this limits visibility into outcomes due to parameter setting changes. For this reason, dynamic parameter adjustment should be avoided. Instead, developers choose parameter sets based on understanding gained by backtesting, and run with them for a while monitoring system performance.
Small budget trading
Small budget trading operates the system in real-time using live data, including execution of trades. Because it is the first exposure to risk from system decisions, exposure is limited by limiting the system’s trading budget. The system is immature in that most of its feedback control mechanisms have not been exercised in current market conditions due to the inherent limitations of paper testing. As such, the new system needs an allowance, not a treasury.
The new system’s trading allowance buys access to feedback signals from the effects that its trades have on the market. As mentioned earlier, risk is inevitable in this situation. A trading strategy must specify the amount of risk it can accept as well as the amount of benefit it expects. Small budget trading demonstrates that the system can, through its control plane, adhere to the specified amount of risk. Small budget trading also most accurately demonstrates whether benefits at least meet expectations.
Comparison with CRISP-DM
While it is comforting that a well-practiced development process can be adapted to developing an ARMM, still more comfort is derived from realizing that Quant’s four-phase process described above is really a specific instance of a widely accepted process model for developing ML governance and risk management, as well as data analytics via the Cross-Industry Standard Process for Data Mining (CRISP-DM). The linked article does an excellent job of defining the process. The main point here is to draw parallels between CRISP-DM and Quant’s process in Table I, below:
Figure 1 illustrates diagrammatically CRISP-DM’s six process phases along with the cyclical nature of the temporal relationships of the phases. Table I shows how the four phases of the Quant process map to CRISP-DM’s phases. (From Wikipedia)
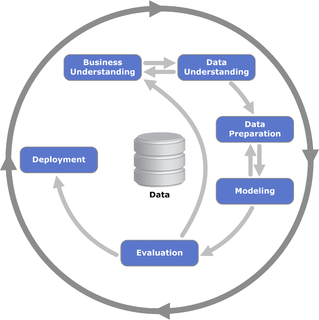
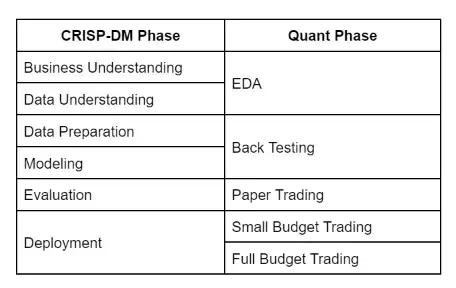
CRISP-DM was developed in Europe in the late 1990s as a process to extract value from data warehouses. It has stood the test of time and is widely used by modern day data scientists–a job title that did not exist when the standard was developed. Today, Data Validation is sometimes called out into its own phase. Here it is considered part of Data Understanding or Data Preparation. A more significant sign of age is a need for an Operation phase after deployment, and back arrow relationship between deployment and evaluation. The need results from the observation made above that there are some aspects of a decision-making system that cannot be evaluated until after deployment of a fully functional system in a real market — so the process should be understood as circular and iterative. (The Quant process handles this with its Small Budget Trading phase.)
Using the CRISP-DM and Quant processes, ARMM developers gain an understanding of what a business expects from an ARMM, the market conditions in which it will operate, and the boundary market conditions under which it will behave in accordance with expectations. A control plane for humans operating an ARMM with failsafe mechanisms, including an off-switch that the business can reach, can be developed and tested in real-world conditions. Safe conditions for testing in production can be established and used along with a migration path to full production usage. This is a process that recognizes the ARMM and its human operators as a more robust system that can be proven worthy of our trust.
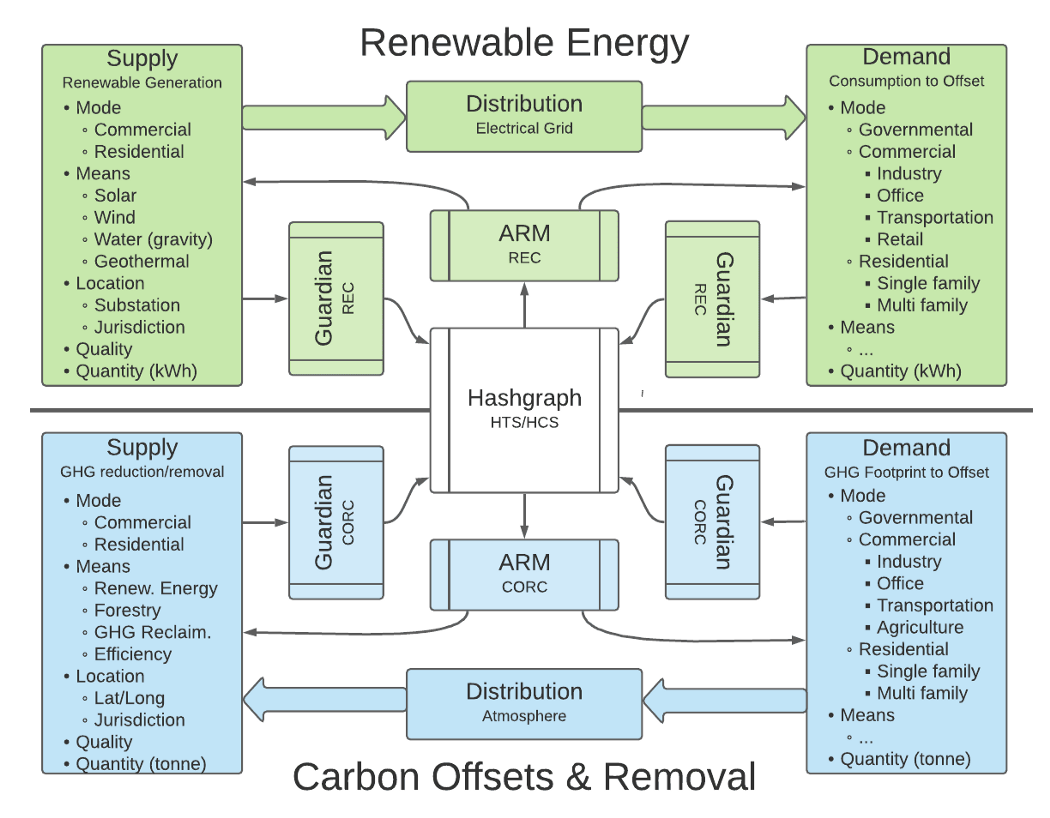
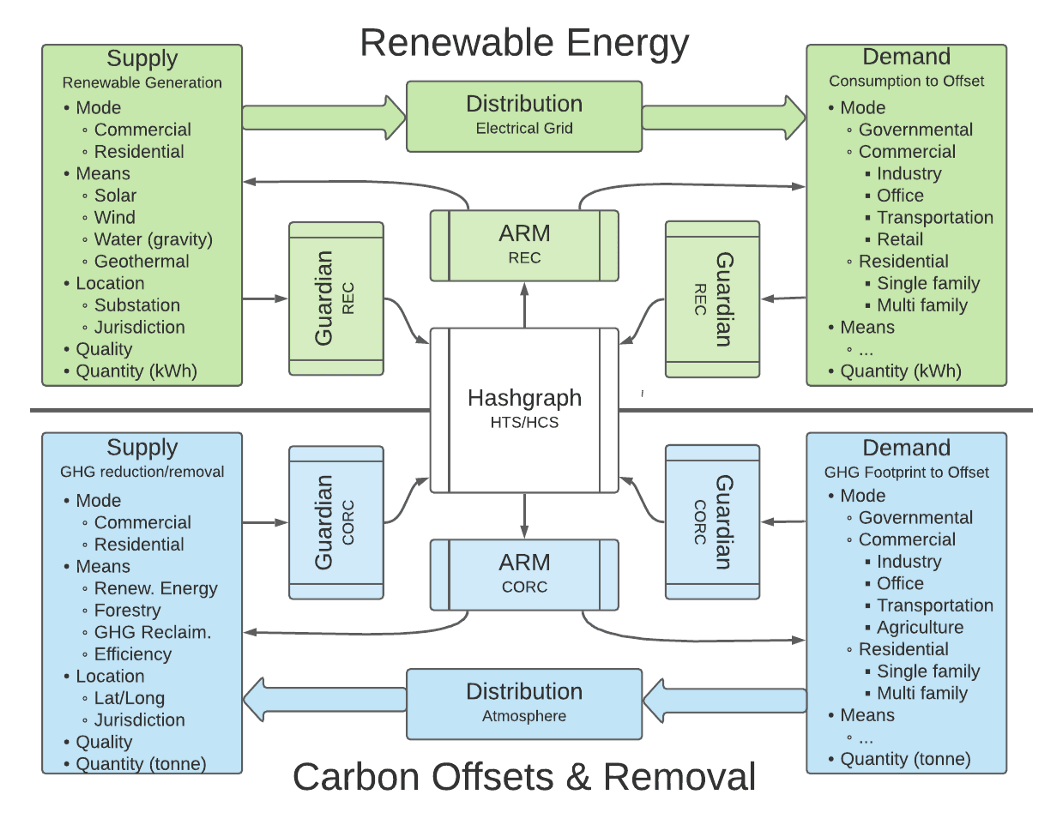
Building in parallel: Hedera’s ARMM infrastructure development
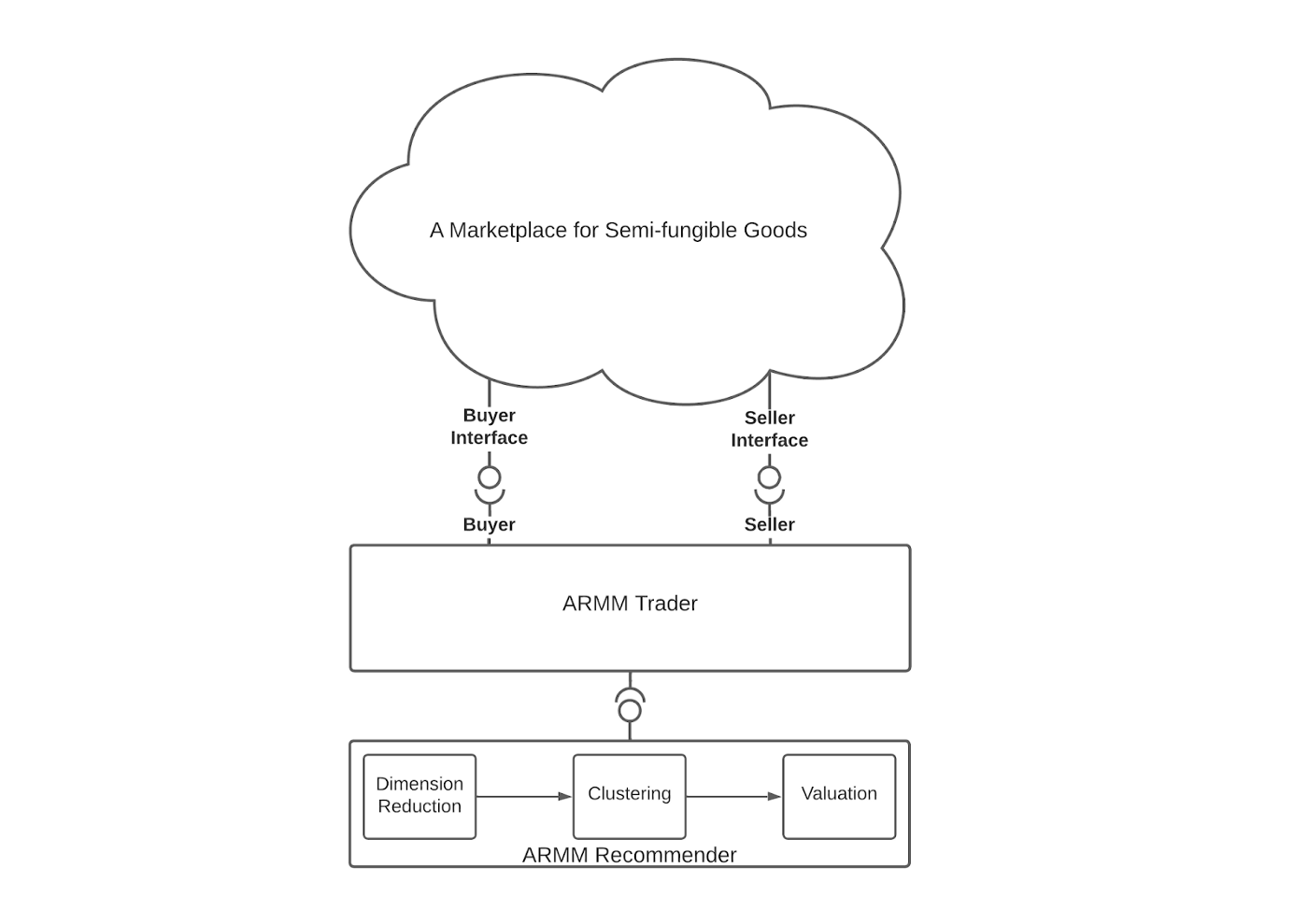
While the research team continues to rigorously research and test the ARMM’s signal processing, price discovery, trading capability, and potential including testing in production, the Hedera ecosystem is developing the core application logic required to deploy ARMMs. The team is focusing on the business logic and accounting enforced on the Hedera public ledger, such as their recently open-sourced Guardian for validating on-chain claims based on real-world actions.
Guardian offers a policy workflow engine that tokenizes climate assets and liabilities, such as offsets and emissions, and it leverages token standards defined by the Interwork Alliance Sustainability Business Working Group and W3C DID Methods. The ARMM open-source exchange architecture will also use Hedera’s recently released Smart Contracts 2.0 with improved scalability to enable the facilitation of these trades.
Further Research & the Road Ahead
Through the HBAR Foundation, BlockScience is consulting with partners Hedera, ObjectComputing, Inc. (OCI) and Tolam Earth to develop an ARMM recommendation engine to test in production using the Quant and CRISP-DM methodologies. OCI’s ARMM instance is slated for deployment into the marketplace for digital environmental assets, e.g., carbon offsets, recently announced by Tolam Earth. This marketplace is a key factor in this ARMM’s development and will supply the ARMM with real-world, real-time, attribute-level data from the assets traded on its platform.
In the short term, we are developing an ARMM that will suggest effective trades on Tolam Earth’s marketplace. Over time, the data will support the development of ARMMs into mature and trusted market makers that make effective trades in Tolam Earth’s marketplace and beyond.
Building in parallel, rather than merely focusing on deploying a wholly custom instance of the ARMM, the Hedera ecosystem is creating an ARMM application design pattern for their infrastructure. This allows applications to focus on the data science aspects of their ARMM designs, and trust the deployment and enforcement of their market designs to the Hedera network.
As this article makes clear, algorithmic trading is a risky business, but algorithmic trading in the form of ARMMs is necessary for efficient, high volume, attribute-based markets. However, we can learn from past efforts and use the most rigorous frameworks for testing and integrating learnings in iterations. We can follow a process that identifies risk, enables risk/benefit analysis, and most importantly allows controlled testing in production against real-world, real-time market activity. Hedera’s framework is being built to support this trust-enabling process.
Carbon markets are just one use case for ARMMs. This new mechanism has exciting potential and our end goal is to generalize its use in a wide range of applications, along with their infrastructure, for buying and selling in partially fungible markets. We look forward to continuing research and collaborations to explore the transformative potential of ARMMs to leverage market impact to solve some of our world’s biggest challenges.
Article by David Sisson, Jessica Zartler, Jamsheed Shorish and Michael Zargham from research by Matt Stephenson, Zargham, Shorish and Sean McOwen with contributions and edits by Wes Geisenberger, Andrew Clark, Jeff Emmett and Daniel Furfari.
About BlockScience
BlockScience® is a complex systems engineering, R&D, and analytics firm. Our goal is to combine academic-grade research with advanced mathematical and computational engineering to design safe and resilient socio-technical systems. We provide engineering, design, and analytics services to a wide range of clients, including for-profit, non-profit, academic, and government organizations, and contribute to open-source research and software development.
About HBAR Foundation
Founded in 2021, the HBAR Foundation was created to fuel development of the Hedera ecosystem by providing grants and other resources to developers, startups and organizations that seek to launch decentralized applications in DeFi, NFTs, CBDCs, ESGs, gaming and other sectors. In addition to providing funding through a streamlined grant process, the HBAR Foundation acts as an integrated force multiplier through expert support across technical, marketing, business development and other operational functions that are required to scale. For additional information or to apply for funding, please visit https://hbarfoundation.org/ or follow the Foundation on twitter @HBAR_foundation.
