
A New Framework for Data Transformation Provenance in Complex Systems Modeling
This piece is introducing and exploring the concept of Content-Addressable Transformers (CATs) from a high-level. CATs are part of the BlockScience team’s research on data driven systems, inspired by our work in the Filecoin ecosystem but applicable far beyond. While this research exists at the design pattern level for the time being, we see it enabling a new frontier of impactful use cases on the content-addressable web. We invite you to join us on the development journey of this exciting new software framework for data provenance in complex systems modeling.
What is a CAT?
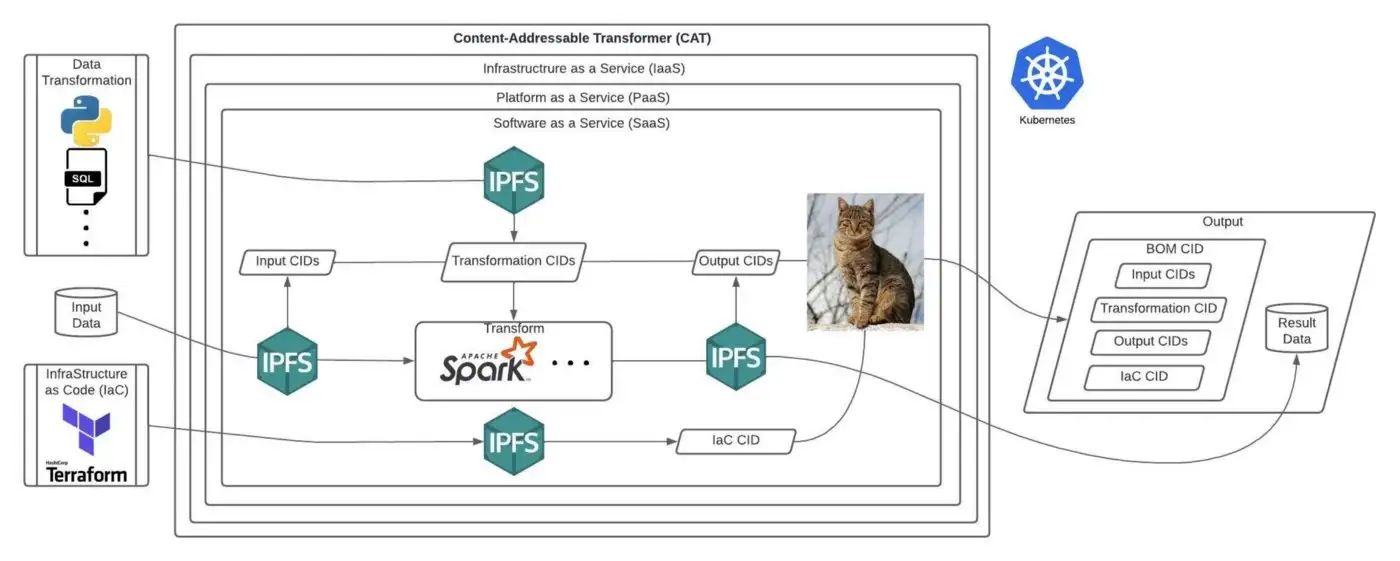
Content-Addressable Transformers (shortened to CATs) are a unified software framework that empowers cross-domain collaboration on data-processing pipelines between decentralized multi-disciplinary teams and organizations. They enable data and process verification and provenance as chains of evidence for retrieval and re-execution via content-addressing the means of processing (input, process, output, infrastructure-as-code). CATs are implemented using the horizontal scaling capacity of Web2 cloud services and enable data provenance using content-identifiers (CIDs) as a means of data transport between services. This framework offers data transformation provenance that is critical for data verification in large-scale open source modeling and data science.
What is Content-Addressing?
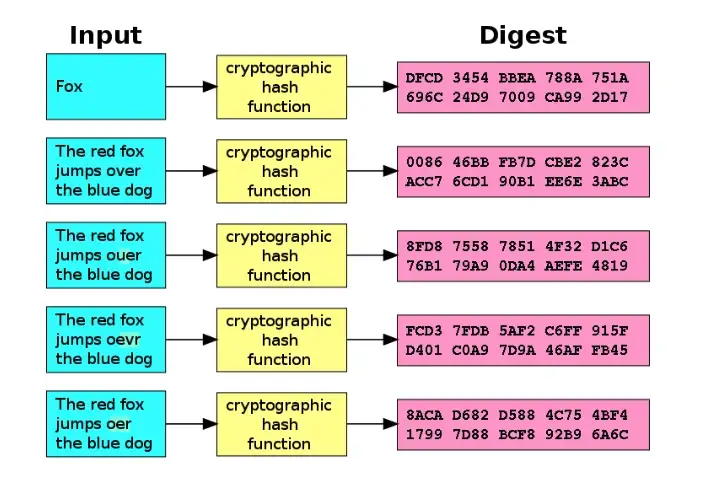
Content-addressing is the process of hashing content, putting it on a distributed network, and using the hash of the content (its “address”) to request that content from the network. So then the “address” (the hash of the content) points to the content itself, not a location on a network that might hold that content (as it would be under a location addressed system, like today’s internet). For example, sometimes you might follow a link and get a 404 error saying that there is nothing at that location. This is because the link is pointing to a location on a server, not to the data itself. With content-addressed data, you can request the data itself, regardless of where it’s stored on a network. The Interplanetary File System (IPFS) documentation explains content-addressing in greater detail.
CATs use content-addressing to find input data, the code for the processing of that data, and instructions for building the system on which the code will run. In this way, CATs define running specific data through specific programs with specific parameters. As a result, a verifiable output is obtained with a receipt of its computational provenance, which is also content-addressed. This process creates a chain of evidence that can be used to verify data sources and the process used to transform it into its present form, for more transparent, verifiable, and reliable data.
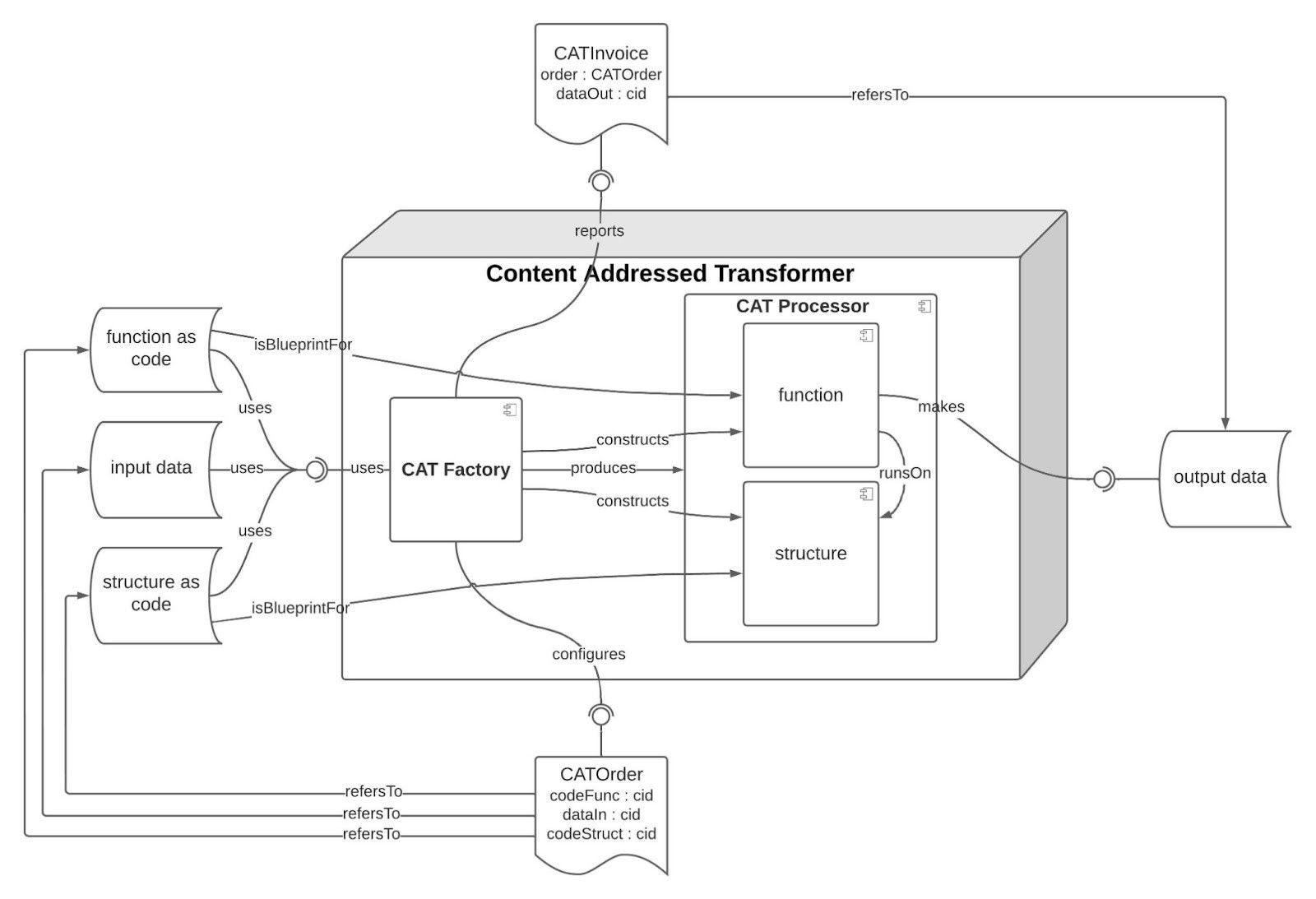
Using the nomenclature of CATs, we can verify the:
- [Infra]Structure as Code: the process of managing and provisioning computation environments through machine-readable definition files
- Function as Code: a user defined data transformation process that processes data according to an instruction set
- Input Data: the data being processed (which can also be an output of a previous CAT)
- Output Data: the output is the result of the input data being processed in a specific way, which can also be a subsequent CAT input
These transformation processes will then be composed into more complex workflows, and more complex compositions can also be content-addressed, and so on. This enables Kubernetes-style containerized computation that’s also content-addressable on decentralized networks like the Interplanetary File System (IPFS).
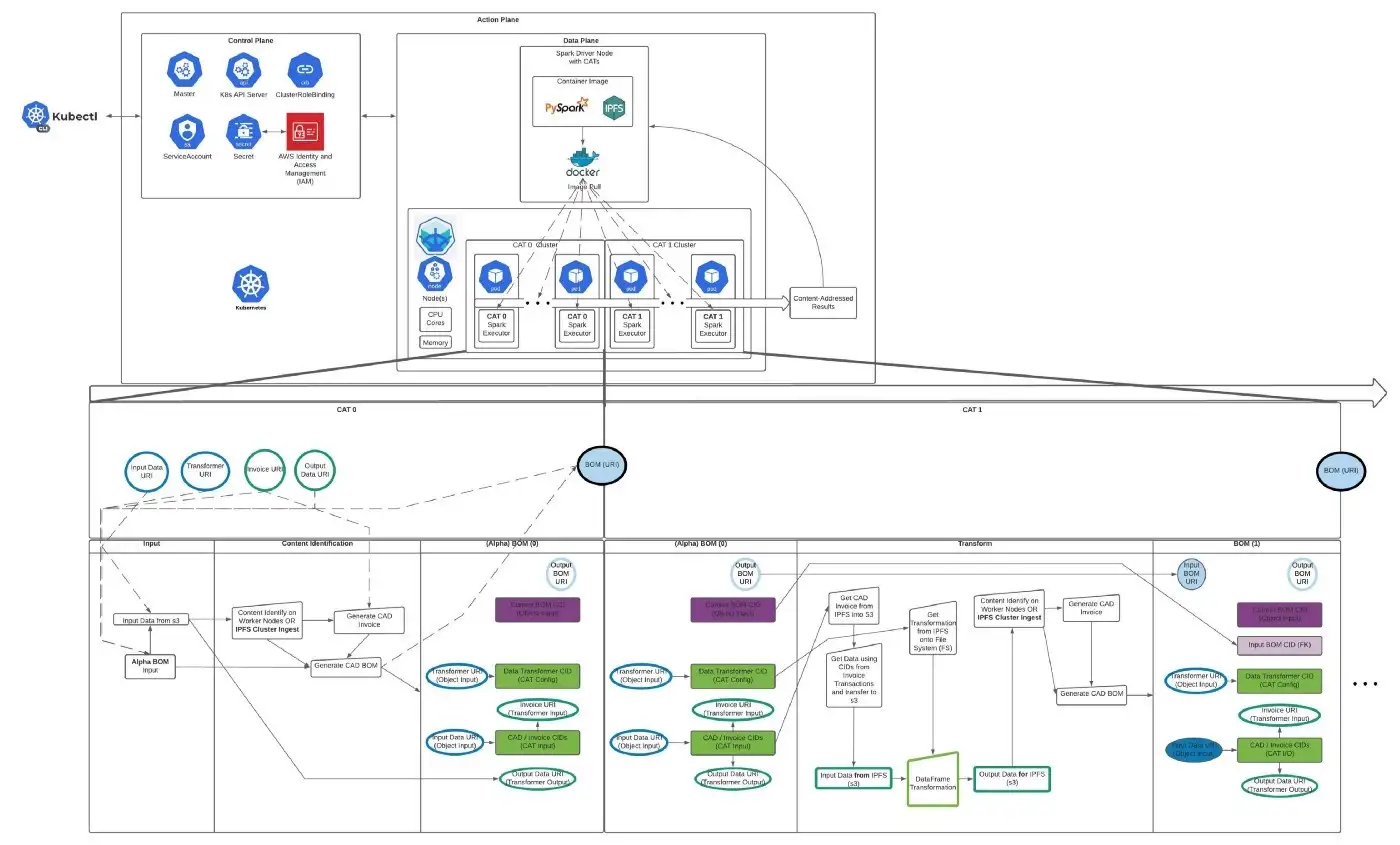
What Can CATs Do?
The design space is ripe for exploration! For something as general purpose as verifiable data and compute, it’s hard to imagine the depths of what’s possible. That being said, we have a few ideas:
👩🔬 Collaborative data science
- Datasets, programming languages, and models are content addressed and stored on IPFS.
- Anyone who wants to rerun an experiment can download exactly the same version of data, infrastructure, and models to work with.
- Results of experiments can be verified and replicated more easily.
- Complex data processes will be containerized so that everyone can recreate the pipeline, then modify the specific part of that pipeline that they’re working on in order to isolate the effect of their changes from the process as a whole.
🌍 Shared tooling for data-driven reasoning about the world
- In a future of open source models and accessible data, CATs could be used to lower the barriers towards public participation in evidence-based exploration of big data models, potentially impacting policy choices.
- Using CATs, citizen data scientists could verify, validate and/or challenge results from models used by corporations, think tanks or governments.
- This could be useful in modeling the impacts of funding cuts on hospital wait times, or climate consequences of further investment in fossil fuels, for example.
🐞 Better bug reporting
- Bug reports for CAT based applications would specify every aspect of the data, infrastructure, and programs that caused the bug.
- Developers could then recreate the exact circumstances that caused the bug.
- This would make troubleshooting and fixing the bug easier.
🎨 Dynamical art
- When a computational process is content-addressed, it has a unique identifier.
- You could create an algorithm that produces cool visual effects, then create an NFT of the CID (content address identifier) of that algorithm.
- Then anyone can run the algo to produce computational art on their unique data, but someone would also own the NFT representing that transformation.
- So the art itself would not be a static thing like an image, but an algorithmic process that operates on whatever data you feed into it.
What’s Next for CATs?
This is the first part of an ongoing research series on CATs. In the future we’ll share a more technical post exploring the mechanisms that make CATs work, and a demo to start to interact with the code. We hope this sparks your imagination and interest in CATs and the content-addressed web!
CATs are part of our blue sky research stream, and are very much a work-in-progress. You can find our technical work on this process in our Github repo: https://github.com/BlockScience/cats, as well as our technical next steps on the project.
If you are interested in supporting further research in this area, experimenting with CATs for your project’s use case, or want to contribute to the codebase and be an early adopter, please reach out to david@block.science.
Content for this article was produced by David Sisson, Joshua Jodesty, Burrrata and Jeff Emmett. Special thanks to Michael Zargham, Jessica Zartler, and Kelsie Nabben for taking the time to review and provide feedback.
